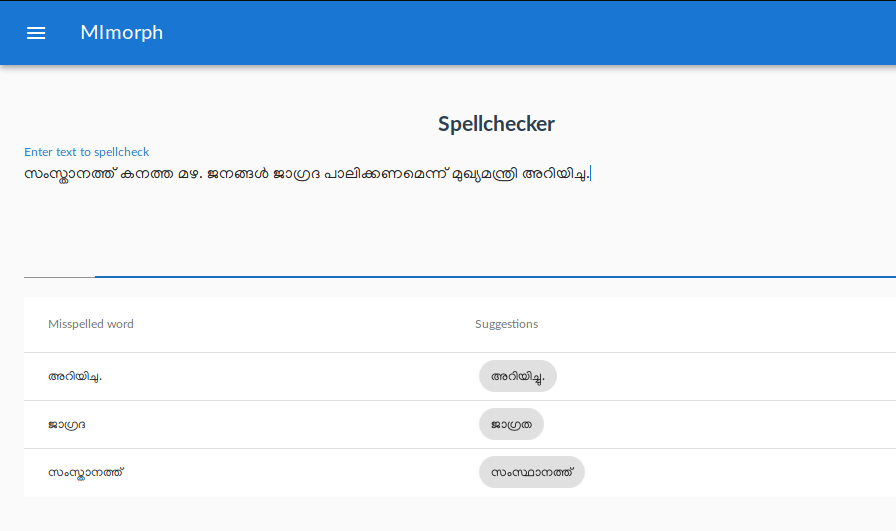
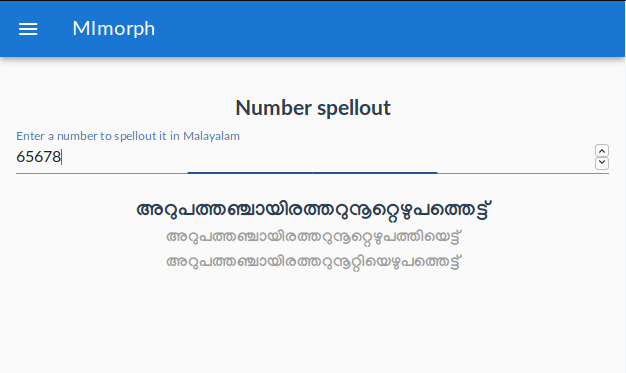
New version of Malayalam morphology analyser
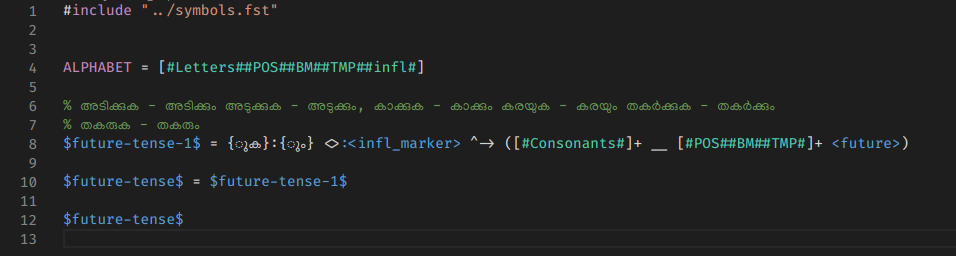
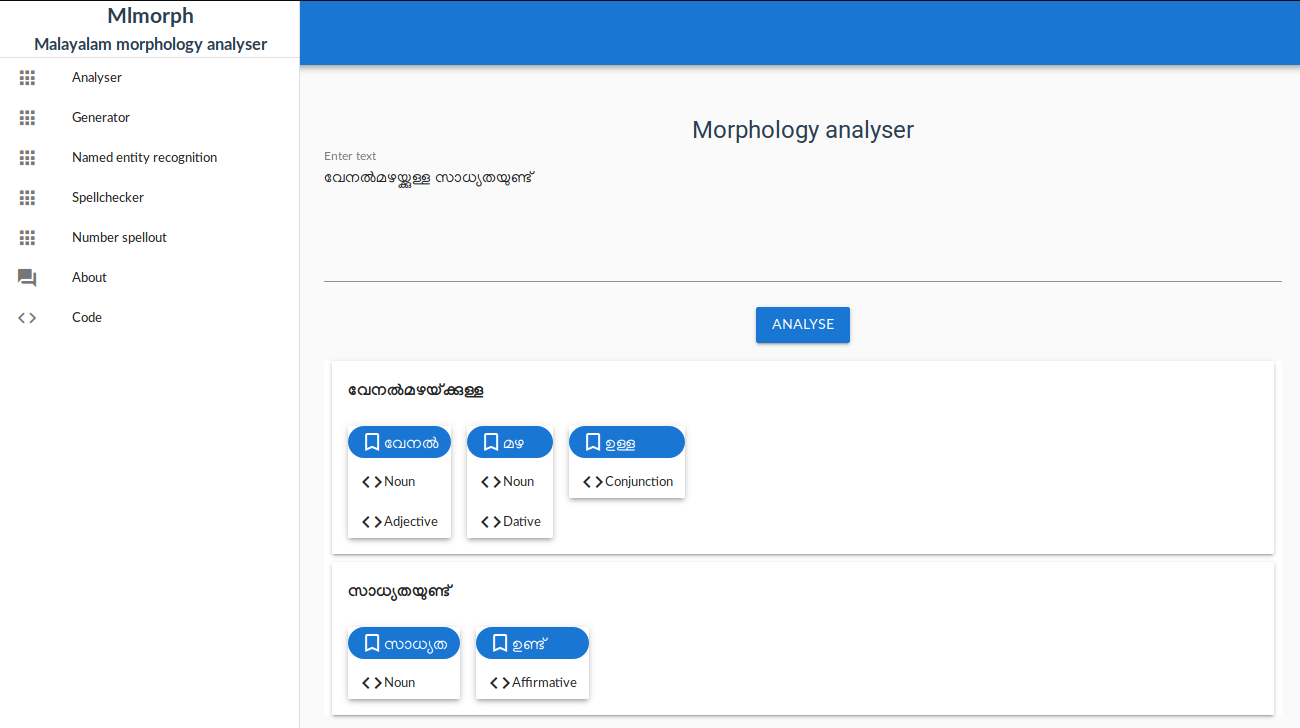
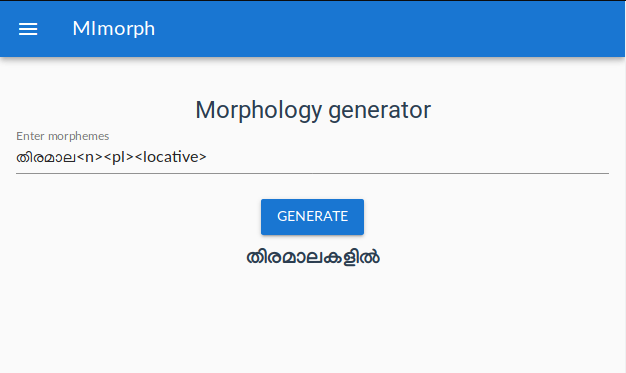
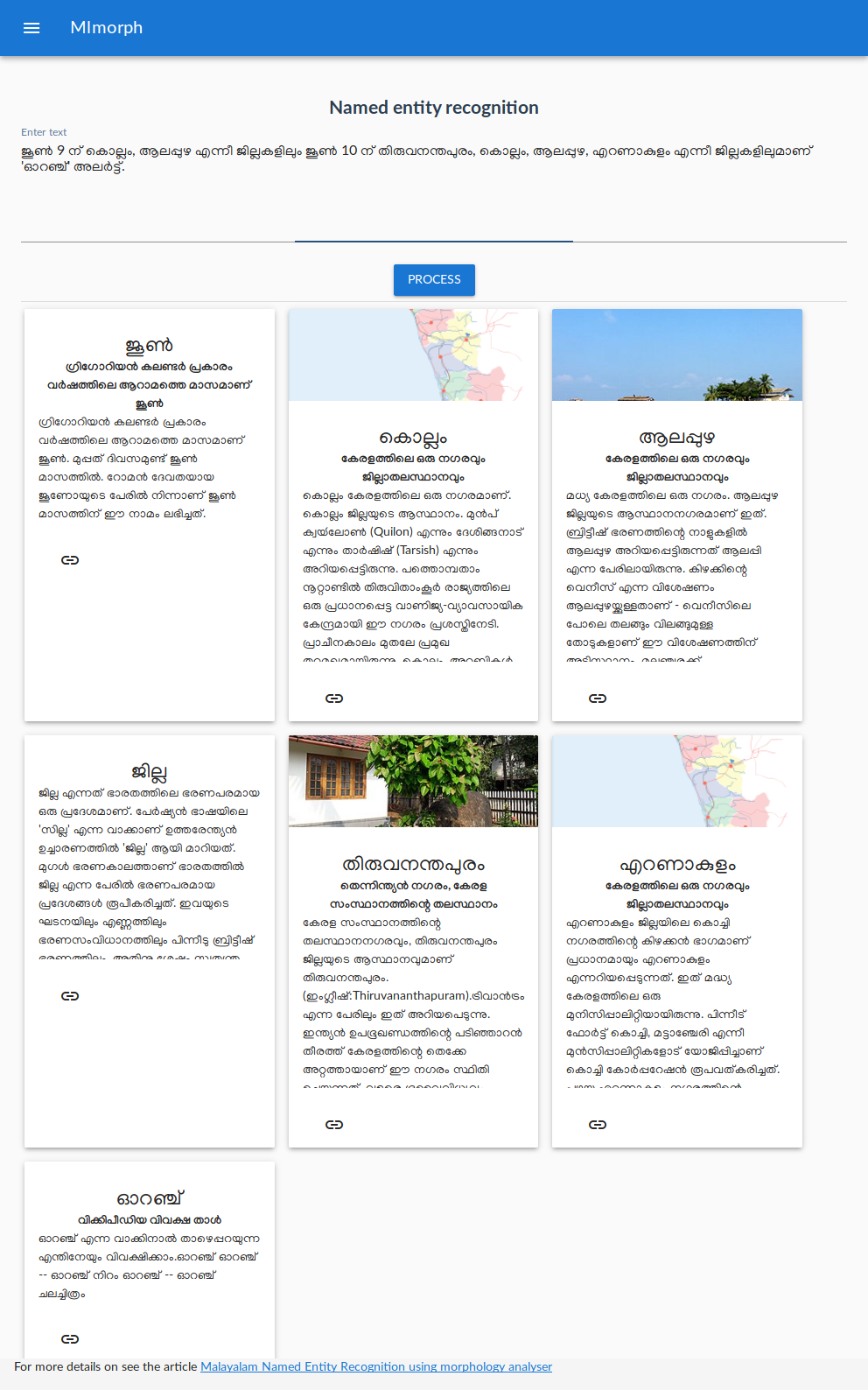
In the previous blog post I explained my efforts to modernize SFST. Since I published SFST python binding and modernized to make it compile in all operating systems, next step was to drop HFST dependency of mlmorph and use the new version of SFST 1.5.0.
mlmorph 1.3.0 has no dependency on HFST and all installation problems in different operating systems and python versions are solved now.
Latest version is also available in pypi.
[Read More]