One of the key components of Mlmorph is its lexicon. The lexicon contains the root words categorized as nouns, verbs, adjectives, adverbs etc. These are the components used with morphological rules to generate the vocabulary of Malayalam. I collected initial lexicon with about 100,000 words from various sources such as Wikipedia, CLDR and many targeted web crawls. One problem with such collected words is they often contains spelling mistakes. Secondly, classifying these words is not possible without the tedious task of a person going through each and every words.
So, I was thinking of a solution which consists of:
- A crawler or multiple targeted crawlers looking for candidate words. For example, I can write script to look for the entire Malayalam wikipedia dump and look for words that are most probably nouns or inflected nouns or words derived out of nouns. This is possible with some kind of pattern matching. For example, a word ending with -യുടെ, -ിന്റെ, -ിൽ, -യെ are most probably noun(we don’t know whether it is pronoun or place name or person name- that require human curation). A word ending with -ക്കുക, -ച്ചു, -ട്ട്, -ിരുന്നു, is most probably a verb.
- A database and an application that helps a person to quickly approve the prediction, remove the misspelled word, edit the word to correct mistakes, choose a correct POS tagging
- A set of scripts that will take the curated words to the lexicon of mlmorph. Also as mlmorph learn new root words, the database will require a refresh since mlmorph start recognizing words related to the new words learned.
Over the last few days, I was working to implement this system. Interestingly, I was also learning and practicing Vuejs. I was amazed by the productivity it gives to quickly build clean and fast modern web applications. So I decide to use that for my curator application. For database I found firebase with Vuefire will be a perfect fit. Vuetify helped to do quick UI styling. Without writing any specific code for database management I got the whole system working.
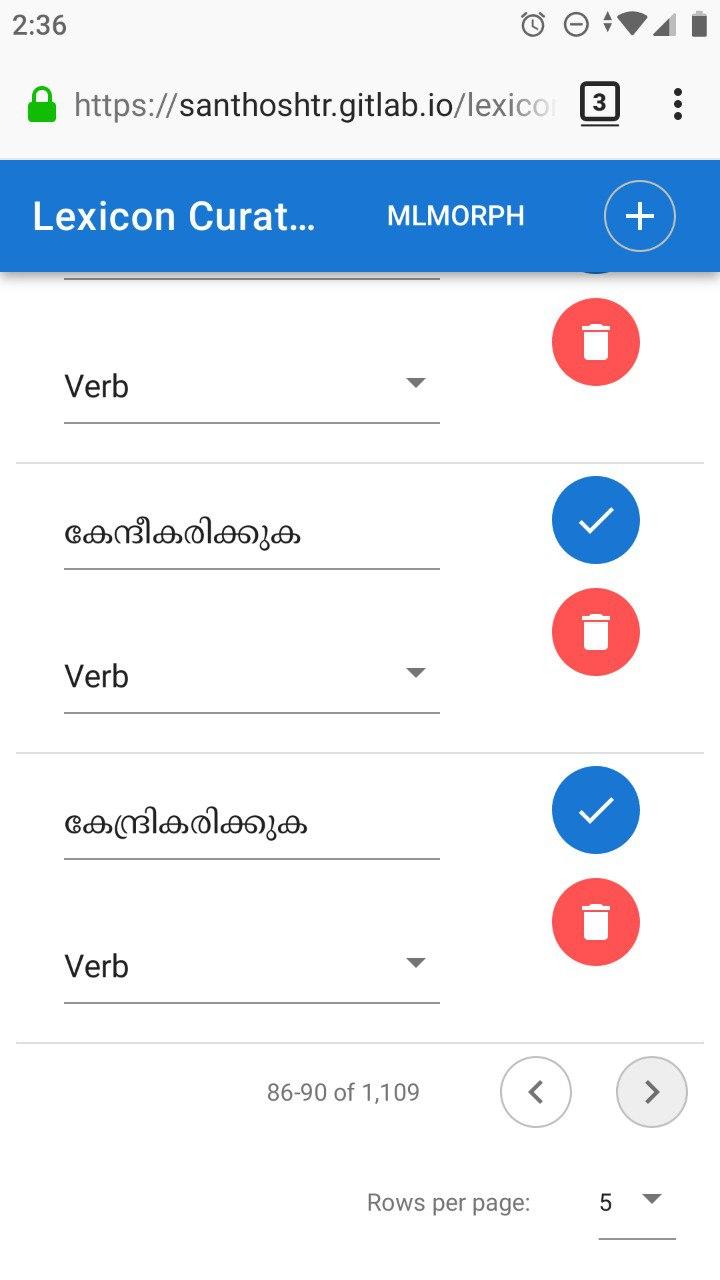
The mobile friendly application allows me to do this otherwise tedious task as a leisure activity. After adding some user authentication, I will make it public and share with some friends. Source code: https://gitlab.com/santhoshtr/lexicon-curator/. Thr mlmorph scripts are at https://gitlab.com/smc/mlmorph