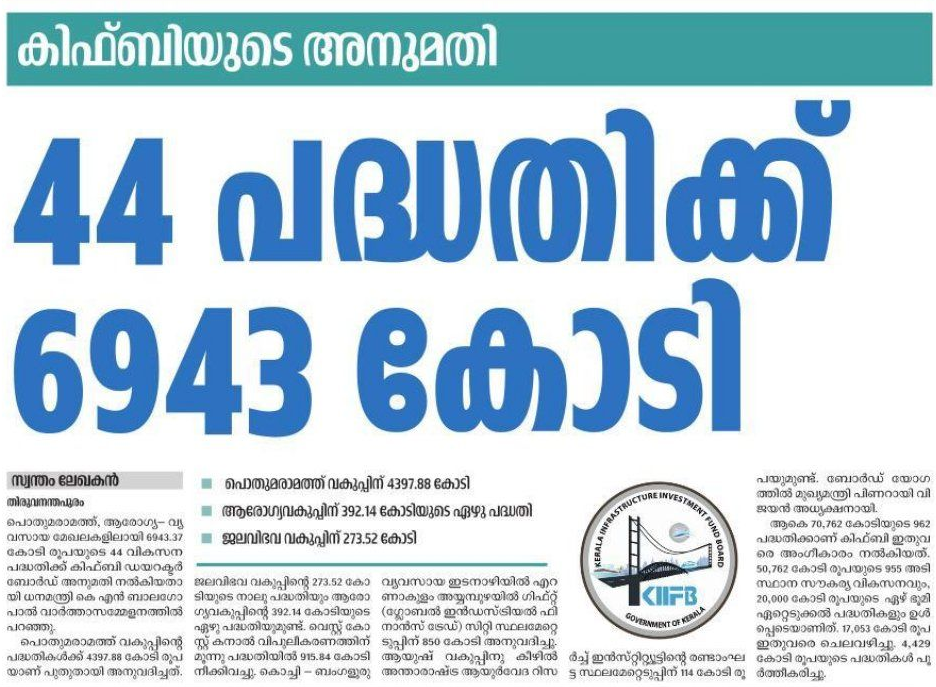
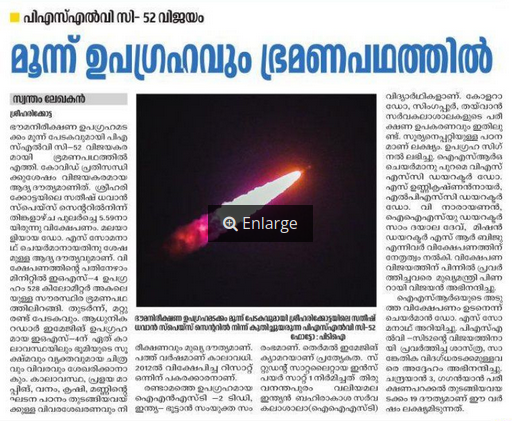
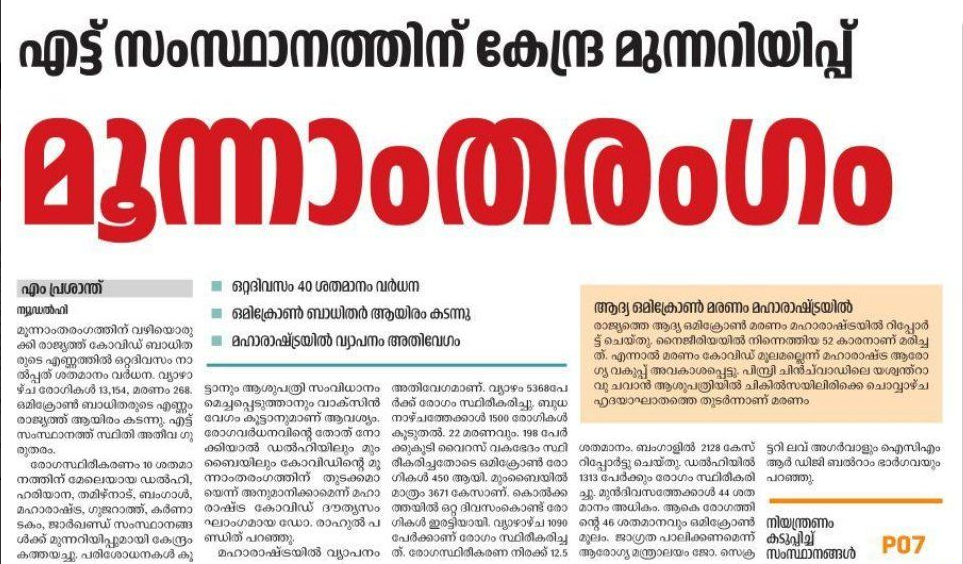
ഈയിടെയായി ദേശാഭിമാനി പത്രത്തിൽ ബഹുവചനങ്ങൾ, പ്രത്യേകിച്ചും തലക്കെട്ടുകളിൽ ഒഴിവാക്കുന്നത് ശ്രദ്ധയിൽ പെട്ടു. ഇത് ഒരു എഡിറ്റോറിയൽ തീരുമാനമാണോയെന്നറിയില്ല. തലക്കെട്ടിൽ ബഹുവചനരൂപമില്ലെങ്കിലും വാർത്തയിൽ അവയുണ്ടുതാനും. ഇത് എല്ലായിടത്തും ഒരുപോലെ കാണുന്നുമില്ല. വെറുമൊരു കൗതുകത്തിനു കുറച്ചു ഉദാഹരണങ്ങൾ കൊടുക്കുന്നു.