Writing a number 6493 as six thousand four hundred and ninety three is known as spellout of that number. The most familiar example of this is in cheques. Text to speech systems also need to convert numbers to words.

The reverse process of this, to convert a phrase like six thousand four hundred and ninety three to number 6493 – the number generation, is also common. In software, it is often required in Speech recognition and in general any kind of semantic analysis of text.
Numbers and its conversion to English words is not really a complex problem to solve with a computer. But how about other languages? In this article, I am discussing the nature of these words in Malayalam and an approach to parse the number and numbers written in words.
Malayalam number spellout
In Malayalam, the spellout of numbers forms a single word. For example, a number 108 is നൂറ്റെട്ട് – a single word. This word is formed by adjective form of നൂറ്(100) and എട്ട്(8). While these two words are glued, Malayalam phonological rules are also applied, resulting this single word നൂറ്റെട്ട്. This word formation characteristics are present for almost all possible numbers you can imagine. Parsing the number നൂറ്റെട്ട് and interpreting it as 108 or converting 108 to നൂറ്റെട്ട് is an interesting problem in Malayalam computing.
I came across this problem while I was trying to develop a dictionary based spellchecker years back. Such a dictionary should have all these single words for all possible numbers, right? Then how big it will be? Later when I was researching on Malayalam morphology analyser, I again encountered this problem. You cannot have all these words in lexicon as entries – it is not practical. At the same time, you should be able to parse these words and and also generate with correct morpho-phonological rules of Malayalam.
Like I mentioned in my introduction article of my Malayalam morphological analyser, project, Malayalam is a heavily agglutinative language. While I was learning the Finite transducer technology, Malayalam number words were one of the obvious candidates to try out. These numbers perfectly model Malayalam word formations. They get agglutinated and inflected, during which morpho-phonological rules get applied. നൂറ്റെട്ടിലായിരുന്നു, നൂറ്റെട്ടിനെ, നൂറ്റെട്ടോ? നൂറ്റെട്ടാം, നൂറ്റെട്ടാമത്തെ, നൂറ്റെട്ടര – All are examples of words you get on top number word നൂറ്റെട്ട്. Also, it is not two word agglutination, പതിനാറായിരത്തൊരുനൂറ്റെട്ട് – 16108 is an example where പതിനാറ്(16), ആയിരം(1000), നൂറ്(100), എട്ട്(8) – all joined to form a single word. In fact this is a common word you often see in literature because of this myth about Lord Krishna. The current year, 2017 is often written as രണ്ടായിരത്തിപ്പതിനേഴ്.
Let us examine a nature of these word formation.
Ones
Numbers between 0 and 9 has words as പൂജ്യം, ഒന്ന്, രണ്ട്, മൂന്ന്, നാല്, അഞ്ച്, ആറ്, ഏഴ്, എട്ട്, ഒമ്പത് respectively. The word ഒമ്പത് is sometimes written as ഒൻപത് too, which is phonetically similar to ഒമ്പത്. Each of these words ending with Virama(്) is sometimes written with Samvruthokaram too. ഒന്ന് – ഒന്നു്, രണ്ടു്, മൂന്നു്, നാലു് etc.
Tens
Number 10 is പത്ത്. Multiples of tens till 80 follows the rough pattern:
Adjective form of [രണ്ട്|മൂന്ന്|നാല്|അഞ്ച്|ആറ്|ഏഴ്|എട്ട്] + പത്.
So, they are ഇരുപത്(20), മുപ്പത്(30), നാല്പത്(40), അമ്പത്(50), അറുപത്(6), എഴുപത്(70), എൺപത്/എമ്പത്(80). But at 90, a new form emerges – തൊണ്ണൂറ് – Which has no root on ഒമ്പത് (9). Instead it is more like something before നൂറ്(100).
The numbers 11-19 are unique words. പതിനൊന്ന്, പന്ത്രണ്ട്, പതിമൂന്ന്, പതിനാല്, പതിനഞ്ച്, പതിനാറ്, പതിനേഴ്, പതിനെട്ട്, പത്തൊമ്പത് respectively.
All other two digit numbers between the multiples of tens follow the following pattern
[Word for 10x] + [Word for Ones]
So, 21 is ഇരുപത്(20)+ ഒന്ന്(1). But to form a single word, An adjective form is used, which is similar to female gender inflection of Malayalam nouns- ഇരുപത്തി + ഒന്ന് . Phonological rules should be applied to combine these two words. The vowel sign ി(i) at the end of ഇരുപത്തി will introduce a new consonant യ(ya). Also the first letter of ഒന്ന് – the vowel ഒ will change to its vowel sign form ൊ. So we get ഇരുപത്തി + യ + ൊന്ന്. It results ഇരുപത്തിയൊന്ന്. This phonological rule is actually Agama Sandhi / ആഗമ സന്ധി as per Malayalam grammer rules. But, ഇരുപത്തിയൊന്ന് has a more propular form, ഇരുപത്തൊന്ന് which is generated by dropping ി + യ from the generation process.
The words for 20s can be generated similarly. ഇരുപത്തിരണ്ട്(22), ഇരുപത്തിമൂന്ന്(23), ഇരുപത്തിനാല്(24), ഇരുപത്തിയഞ്ച്/ഇരുപത്തഞ്ച്(25), ഇരുപത്തിയാറ്/ഇരുപത്താറ്(26), ഇരുപത്തിയേഴ്/ഇരുപത്തേഴ്(27), ഇരുപത്തിയെട്ട്/ഇരുപത്തെട്ട്(28), ഇരുപത്തിയൊമ്പത്/ഇരുപത്തൊമ്പത്(29). For all other two digit numbers the pattern is same. Note that തൊണ്ണൂറ് (90) has the prefix form തൊണ്ണൂറ്റി. So 98 is തൊണ്ണൂറ്റിയെട്ട്/തൊണ്ണൂറ്റെട്ട്.
Hundreds
100 is നൂറ്. Its prefix form is നൂറ്റി. Multiples of 100s is somewhat similar to multiples of 10s we saw above. They are ഇരുന്നൂറ്(200), മുന്നൂറ്(300), നാനൂറ്(400), അഞ്ഞൂറ്(500), ആറുനൂറ്(600), എഴുന്നൂറ്(700), എണ്ണൂറ്(800), തൊള്ളായിരം(900). Here also the 900 deviates from others. The word is related to 1000(ആയിരം) than 100 – Just like the case of 90-തൊണ്ണൂറ് we discussed above.
Forming 3 digits numbers is, in general the prefix of multiple of hundred followed by Tens we explained above. So 623 is അറുനൂറ് + ഇരുപത്തിമൂന്ന് = അറുനൂറ്റിയിരുപത്തിമൂന്ന് or the more popular and short form അറുനൂറ്റിരുപത്തിമൂന്ന്. 817 is എണ്ണൂറ്റി+ പതിനേഴ് = എണ്ണൂറ്റിപ്പതിനേഴ് with gemination of consonant പ as per phonological rule. 999 is തൊള്ളായിരത്തിത്തൊണ്ണൂറ്റിയൊമ്പത് or തൊള്ളായിരത്തിത്തൊണ്ണൂറ്റൊമ്പത് or തൊള്ളായിരത്തിത്തൊണ്ണൂറ്റിയൊൻപത്.
Numbers between 100-199 may optionally prefixed by ഒരു – Adjective form of ഒന്ന്(1). 101 – ഒരുന്നൂറ്റിയൊന്ന് 122-ഒരുന്നൂറ്റിയിരുപത്തിരണ്ട് etc. നൂറ്(100) can be also ഒരുന്നൂറ്
Thousands
1000 is ആയിരം. ആയിരത്തി is prefix for all other 4 digit numbers till 1 lakh(ലക്ഷം 100000). Multiples of 1000 can be generated by suffixing ആയിരം. For example, 4000 is നാല് + ആയിരം = നാലായിരം. 6000 – ആറായിരം. But 5000 is അയ്യായിരം, and അഞ്ചായിരം is less popular version. 8000 is എട്ട് + ആയിരം = എട്ടായിരം, but എണ്ണായിരം is popular form. 10000 is പത്ത് + ആയിരം = പത്തായിരം. But പതിനായിരം is the more familiar version. പതിനായിരം is the suffix for multiples of 10K. They are ഇരുപതിനായിരം, മുപ്പതിനായിരം, നാല്പതിനായിരം, അമ്പതിനായിരം, അറുപതിനായിരം, എഴുപതിനായിരം, എൺപതിനായിരം, തൊണ്ണൂറായിരം. 3000 is മുവ്വായിരം than മൂന്നായിരം. So 73000 is എഴുപത്തിമുവ്വായിരം or എഴുപത്തിമൂന്നായിരം.
Numbers between 1000-1999 may optionally prefixed by ഒരു – Adjective form of ഒന്ന്(1). 1008 – ഒരായിരത്തിയെട്ട് 1122-ഒരായിരത്തിയൊരുന്നൂറ്റിയിരുപത്തിരണ്ട് etc. ആയിരം(1000) can be also ഒരായിരം.
Lakhs & Crores
100, 000 is ലക്ഷം. ലക്ഷത്തി is prefix. 1,00, 00, 000 is കോടി. കോടി itself is prefix. 12,00,90 is പന്ത്രണ്ടുലക്ഷത്തിത്തൊണ്ണൂറ്. 99,00,00,00,00,00,00 is തൊണ്ണൂറ്റൊമ്പതുലക്ഷംകോടി.
Why morphology analyser?
From the above explanation of word formation for numbers in Malayalam, one can see that there are patterns and there are lot of exceptions. But still, isn’t it possible to write a generator using just a rule based program in a programming language. I would agree. Yes, it is possible. But other than mapping these numbers to word forms, handling exceptional rules, there are a few other things also we saw. When words are agglutinated, there are phonological rules in action. Also, I said that these words can be inflected again. We also want the bidirectional conversion – not just word generation, but converting those words back into a number. All these will make such a program so complicated and it has to duplicate so many things from morphology analyser. That is why I used morphology analyser here.
What are the morphemes in a string like ആയിരത്തിത്തൊള്ളായിരത്തിത്തൊണ്ണൂറ്റിയാറ്? ആയിരം, തൊള്ളായിരം, തൊണ്ണൂറ്, ആറ്? Sounds good, but we see that തൊള്ളായിരം is ഒമ്പത്, നൂറ്. and തൊണ്ണൂറ് is ഒമ്പത്, പത്ത്. So expanding it, we get ആയിരം, ഒമ്പത്, നൂറു, ഒമ്പത്, പത്ത്, ആറ്. But this sequence does not make any sense of the single word it created. What is missing? Can we consider തൊള്ളായിരം, തൊണ്ണൂറ് as single morphemes? We can, but…
- If തൊള്ളായിരം is a morpheme, it means, it is in a lexicon. That makes all other 3 digit number also eligible to be listed as items in lexicon. So ultimately, we go back to the large lexicon/dictionary issue I mentioned in the beginning of the article.
- Semantically, any number spellout is originated from Ones and their place value. So തൊണ്ണൂറ് is 9
.
I have not seen any morphology analyser dealing with number spellout. It seems Malayalam numbers are so unique in this aspect. I read a few academic papers on dealing with this complexity using Rule based approaches(See References) and an automata like paradigm language(Richard Gillam – A Rule-Based Approach to Number Spellout).
The approach I derived after trying out some choices is as follows:
- Introduce morphology tags for positional values. This is similar to POS tags, but here we apply for number spellouts.
, , , , , are those tags. - Parse a spellout to reach the atomic morphemes in a number spellout – they are ഒന്ന്, രണ്ട്, മൂന്ന്, നാല്, അഞ്ച്, ആറ്, ഏഴ്,എട്ട്, ഒമ്പത്, പൂജ്യം.
- These morphemes will have the tags mentioned above.
To illustrate this, let use use some examples,
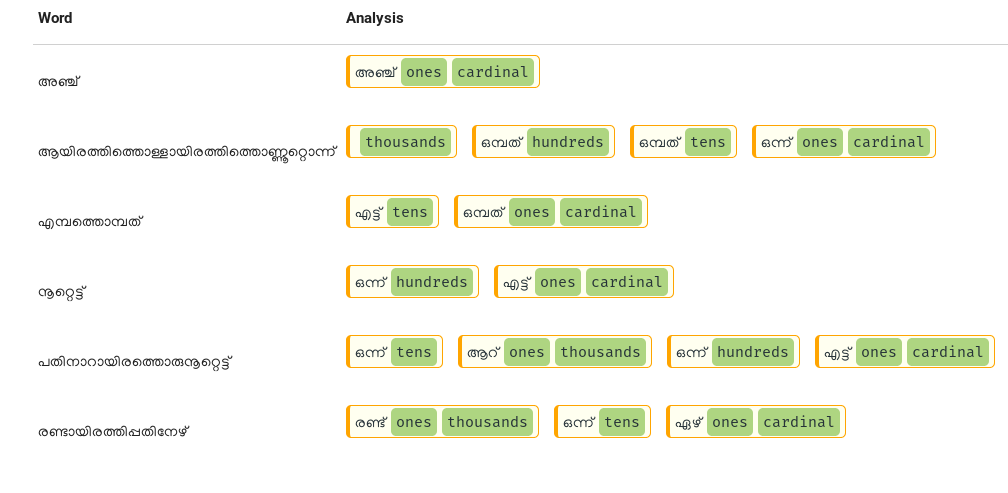
As you can observe, only the atomic numbers are used as morphemes and place values are indicated using tags. You can also see that the analysis is easy to interpret for a program to generate the number.
For example, if the analysis is രണ്ട്
2*1*1000 + 1*10 + 7*1 = 2000+10+7 = 2017
I said that, the advantage of morphology analyser is you can generate the word from analysis strings. The bidirectional property. This means, if you have a number, you can generate the spellout. For that we first need to some maths on the number. For example, for same number 2017, we can divide incrementally by lakhs, thousands, hundreds, tens and arrive at the following formation
2017 = 2*1000 + 0*100 + 1*10+ 7*1
Which can be converted to:
രണ്ട്<thousands>ഒന്ന്<tens>ഏഴ്<ones>
The morphology analyser can easily generate the word രണ്ടായിരത്തിപ്പതിനേഴ് by applying all grammatical rules.
If you are eager to try out this conversion, I wrote a quick javascript based number to word convertor using the APIs of morphology analyser.
See the Pen Malayalam number parser by Santhosh Thottingal (@santhoshtr) on CodePen.
I did not write a convertor from the spelled out word to number. You are free to write one. The web interface of mlmorph is available for trying out some analysis too – https://morph.smc.org.in/
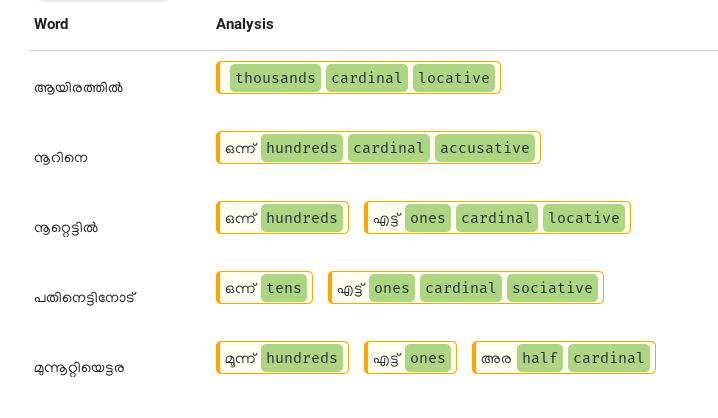
Inflections
Some illustrations on inflected spellout analysis
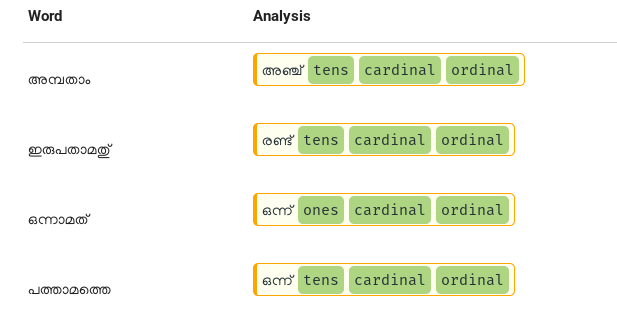
Ordinals
Ordinal form of numbers are used to show position. Examples are first, third etc. In Malayalam examples are ഒന്നാം, പതിനെട്ടാം ഏഴാമത്, ഒമ്പതാമത്തെ etc. Supporting those forms is just like inflections. See the below screenshot
Technical details
- The source code of the mlmorph analyser is at http://github.com/smc/mlmorph
- The specific morphology rules for Malayalam numbers are in this file: https://github.com/smc/mlmorph/blob/master/num.fst
- mlmorph has python API as well as web API. See the documentation at http://github.com/smc/mlmorph. Here is an example of web api: https://morph.smc.org.in/api/analyse?text=മുപ്പത്തൊന്നര
- The system can support numbers till 99,00,00,00,00,00,00 That is Ninety nine lakh crores
Known issues
- Some commonly used forms like മുപ്പത്തിമുക്കോടി is not supported yet.There are also variations like മുവ്വായിരം, മൂവായിരം.
- If there are are multiple ways to generate a number word, the system generates all such forms. But some of these forms may be very obscure and not used at all.
- There is a practice to insert space after some prefixes like ആയിരത്തി, ലക്ഷത്തി, കോടി. In the model I assumed the words are generated as single word.
Summary
We analysed the word formation for the spellout of the numbers in Malayalam. Usage of morphology analyser for analysis and generation of these word forms are introduced. A demo program that converts numbers to its word forms considering all morphophonological rules are presented. Algorithm for spelled out word to number conversion is given with example. Programmable API and Web API is given for the system.