Malayalam is a highly inflectional and agglutinative language. This has posed a challenge for all kind of language processing. Algorithmic interpretation of Malayalam’s words and their formation rules continues to be an untackled problem. My own attempts to study and try out some of these characteristics was big failure in the past. Back in 2007, when I tried to develop a spellchecker for Malayalam, the infinite number of words this language can have by combining multiple words together and those words inflected was a big challenge. The dictionary based spellechecker was a failed attempt. I had documented these issues.
I was busy with my type design projects for last few years, but continued to search for the solution of this problem. Last year(2016), during Google summer of code mentor summit at Google campus, California, mentors working on language technology had a meeting and I explained this challenge. It was suggested that I need to look at Finnish, Turkish, German and such similarly inflected and agglutinated languages and their attempts to solve this. So, after the meeting, I started studying some of the projects – Omorfi for Finnish, SMOR for German, TRMorph for Turkish. All of them use Finite state transducer technology.
There are multiple FST implementation for linguistic purposes – foma, XFST{.new} – The Xerox Finite State Toolkit, SFST{.new} – The Stuttgart Finite State Toolkit and HFST – The Helsinki Finite State Toolkit. I chose SFST because of good documentation(in English) and availability of reference system(TRMorph, SMOR). And now we have mlmorph – Malayalam morphology analyser project in development here: https://github.com/santhoshtr/mlmorph
I will document the system in details later. Currently it is progressing well. I was able to solve arbitrary level agglutination with inflection. Nominal inflection and Verbal inflections are being solved one by one. I will try to provide a rough high level outline of the system as below.
- Lexicon: This is a large collection of root words, collected and manually curated, classified into various part of speech categories. So the collection is seperated to nouns, verbs, conjunctions, interjections, loan words, adverbs, adjectives, question words, affirmatives, negations and so on. Nouns themselves are divided to pronouns, person names, place names, time names, language names and so on. Each of them get a unique tag and will appear when you analyse such words.
- Morphotactics: Morphology rules about agglutination and inflection. This includes agglutination rules based on Samasam(സമാസം) – accusative, vocative, nominative, genitive, dative, instrumental, locative and sociative. Also plural inflections, demonstratives(ചുട്ടെഴുത്തുകൾ) and indeclinables(അവ്യയങ്ങൾ). For verbs, all possible tense forms, converbs, adverbal particles, concessives(അനുവാദകങ്ങൾ) and so on.
- Phonological rules: This is done on top of the results from morphotactics. For example, from morphotactics, ആൽ
, തറ , ഇൽ will give ആൽ തറ ഇൽ . But after the phonological treatment it becomes, ആൽത്തറയിൽ with consonant duplication after ൽ, and ഇ becomes യി. - Automata definition for the above: This is where you say nouns can be concatenated any number of times, following optional inflection etc in regular expression like language.
- Programmable interface, web api, command line tools, web interface for demos.
What it can do now? Following screenshot is from its web demo. You can see complex words get analysed to its stems, inflections, tense etc.
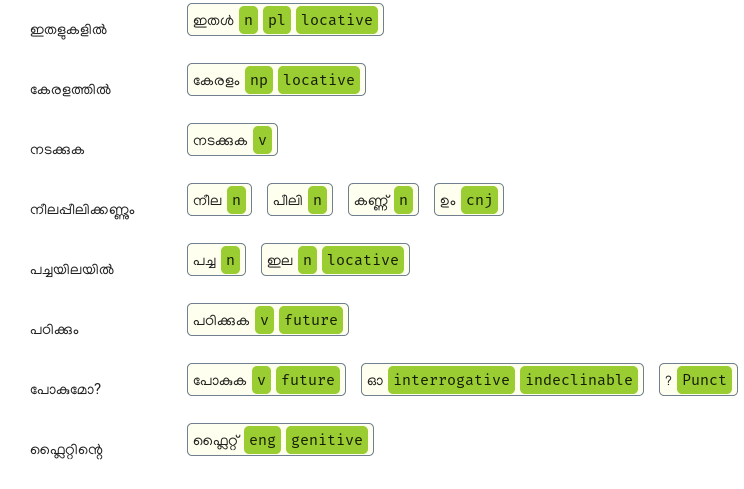 Note that this is bidirectional. You can give a complex word, it will give analysis. Similarly when you give root words and POS tags, it will generate the complex word from it. For example:
Note that this is bidirectional. You can give a complex word, it will give analysis. Similarly when you give root words and POS tags, it will generate the complex word from it. For example:
ആടുക
Covering all possible word formation rules for Malayalam is an ambitious project, but let us see how much we can achieve. Now the effort is more on linguistic aspects of Malayalam than technical. I will update about the progress of the system here.