This is a blog post version a paper titled “Question-to-Question Retrieval for Hallucination-Free Knowledge Access: An Approach for Wikipedia and Wikidata Question Answering” available at https://arxiv.org/abs/2501.11301.
In the world of Large Language Models (LLMs) and question answering systems, hallucination - where models generate plausible but incorrect information - remains a significant challenge. This is particularly problematic when dealing with encyclopedic knowledge sources like Wikipedia, where accuracy is paramount. Today, I’ll discuss a novel approach that addresses this challenge through question-to-question retrieval.
The Problem with Traditional RAG
Current Retrieval-Augmented Generation (RAG) systems face a fundamental challenge: the semantic gap between questions and document passages. When a user asks “Where is the Eiffel Tower located?”, the system tries to match this against passages like “The Eiffel Tower is located in Paris, France.” Despite containing the answer, these passages often yield relatively low similarity scores (typically 0.4-0.7) due to their different structural patterns:
- Questions are interrogative
- Passages are declarative
- Key answer terms may have low weight in the vector representation
This structural mismatch leads to suboptimal retrieval and often requires complex workarounds like question reformulation or hybrid search approaches.
You can see this in action with the following Python code snippet:
qn = "Where is the Eiffel tower located at?"
ans = """
The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France.
It is named after the engineer Gustave Eiffel, whose company designed and built the tower from 1887 to 1889.
Locally nicknamed \"La dame de fer\" (French for \"Iron Lady\"), it was constructed as the centerpiece of the 1889 World's Fair, and to crown the centennial anniversary of the French Revolution.
Although initially criticised by some of France's leading artists and intellectuals for its design, it has since become a global cultural icon of France and one of the most recognisable structures in the world
"""
qnEmbedding = embed_fn(qn)
ansEmbedding = embed_fn(ans)
similarity = cosine_similarity(qnEmbedding, ansEmbedding)
print(f"{qn}\t{similarity}")
# Output: "Where is the Eiffel tower located at?" 0.7 with gemini-1.5-flash and text-embedding-004 embeddings
In this example, the similarity score is only 0.7, indicating a suboptimal match. You can also observe that as the passage length increases, the similarity score tends to decrease. Also, if you move the question to a different form like “What is the location of the Eiffel tower?”, the similarity score may further decrease. The position of the sentence in the passage also affects the similarity score. If the answer is at the beginning of the passage, the similarity score may be higher than if it is at the end.
Let me show you a more realistic example. Following passage is from Barack Obama’s Wikipedia page:
Obama was born in Honolulu, Hawaii. He graduated from Columbia University in 1983 with a Bachelor of Arts degree in political science and later worked as a community organizer in Chicago. In 1988, Obama enrolled in Harvard Law School, where he was the first black president of the Harvard Law Review. He became a civil rights attorney and an academic, teaching constitutional law at the University of Chicago Law School from 1992 to 2004. In 1996, Obama was elected to represent the 13th district in the Illinois Senate, a position he held until 2004, when he successfully ran for the U.S. Senate. In the 2008 presidential election, after a close primary campaign against Hillary Clinton, he was nominated by the Democratic Party for president. Obama selected Joe Biden as his running mate and defeated Republican nominee John McCain.
If we use Gemini 1.5 Flash model and text-embedding-004 model to find the similarity between the question and the passage, we get the following results:
| Question | Similarity Score |
|---|---|
| Where was Barack Obama born? | 0.68 |
| Which university did Obama graduate from? | 0.71 |
| What year did Obama graduate? | 0.70 |
| Where did Obama work as a community organizer? | 0.57 |
| Who is the first black president of Harvard Law Review? | 0.55 |
| From what years did Obama teach at University of Chicago Law School? | 0.75 |
| When was Obama first elected to the Illinois Senate? | 0.67 |
| When did Obama run for U.S. Senate? | 0.66 |
| Who was Obama’s running mate in the 2008 presidential election? | 0.63 |
| Who did Obama defeat in the 2008 presidential election? | 0.58 |
| Who defeated John McCain in the 2008 presidential election? | 0.63 |
| What political party nominated Obama for president? | 0.58 |
| Obama birth place | 0.64 |
The Question-to-Question Approach
Instead of trying to bridge the semantic gap between questions and passages, what if we transformed the problem into a question-to-question matching task? Here’s how it works:
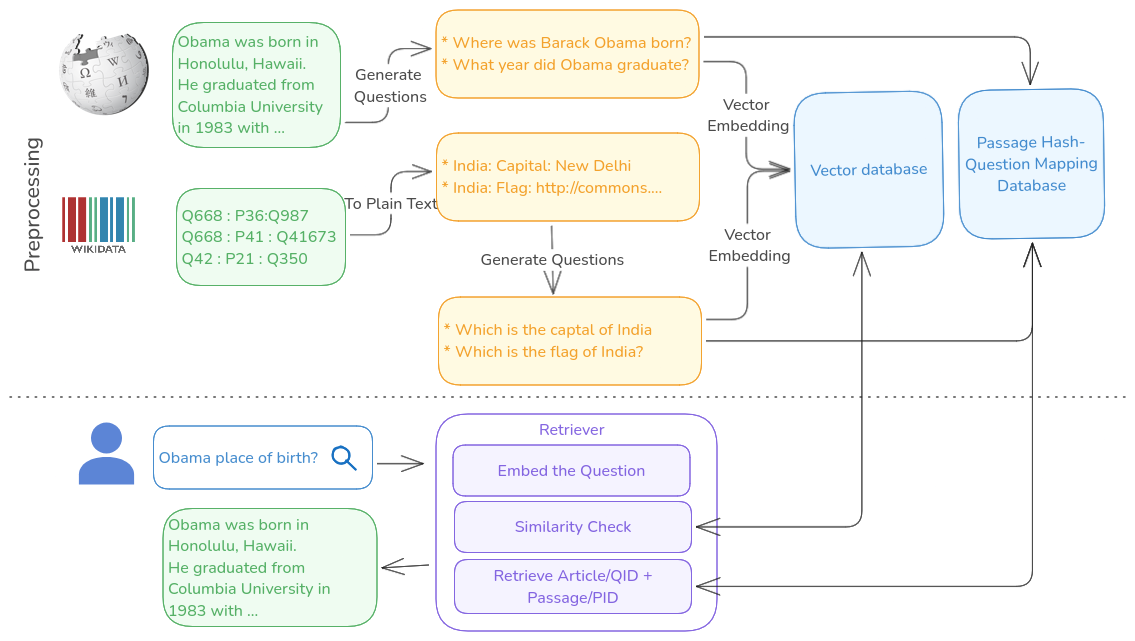
1. Indexing Phase
- For each Wikipedia paragraph, an instruction-tuned LLM generates all possible questions it could answer
- Questions are embedded into vectors using a text embedding model
- A vector store maps these question embeddings back to their source paragraphs
- Each paragraph gets a unique hash for efficient retrieval. This pre-processing step require parsing the Wikipedia content and identifying the paragraphs or atomic encyclopedic units to be precise.
2. Query Phase
- User’s question is embedded into the same vector space
- System finds the most similar pre-generated question
- The corresponding paragraph is retrieved using the stored hash
- Original Wikipedia content is presented to the user
The key innovation here is that we’re comparing semantically similar structures (questions to questions), which leads to much higher similarity scores (> 0.9) and more precise retrieval.
As you can see in the following table, the similarity scores are significantly higher when comparing questions to questions. To make it more realistic, let use mimic users queries as incomplete sentences, often missing question words and occasional spelling mistakes.
| User Query | Most Similar Generated Question | Similarity Score |
|---|---|---|
| “Obama’s birthplace?” | “Where was Obama born?” | 0.91 |
| “France nuclear energy percentage?” | “What percentage of France’s electricity is nuclear?” | 0.92 |
| “How many people died in chernobyl accident” | “How many people died in chernobyl disaster” | 0.97 |
| “How many people died in chernobyl” | “How many people died in chernobyl disaster” | 0.97 |
| “Deaths chernobyl accident” | “How many people died in chernobyl disaster” | 0.90 |
| “Mayor of paris” | “Who is the current mayor of paris?” | 0.93 |
| “longest river in Africa” | “Which is the longest river in Africa?” | 0.96 |
| “length of Nile” | “What is the total length of Nile river?” | 0.93 |
Handling Wikidata Integration
The system also works with Wikidata’s structured data by:
- Converting triples into natural language statements
- Get the triplet: Q668:P39:Q987
- Convert to lables: “India: Capital: New Delhi”
- Generating questions for each statement
- “What is the capital of India?”
- “Where is India’s capital located?”
- Creating vector embeddings for these questions
Real-world Performance
Traditional RAG approaches involves more steps after retrieval to generate the answer. In Question-to-Question retrieval, we eliminate the re-ranking and answer generation steps. Once a passage is retrieved, it is directly presented to the user. In a real world scenario, a user enters a question and the response is pag navigation and scrolling to the relevant section of the page.
NOTE: The Wiki interface shown in the video is a prototype system I built for exploration purposes. As mentioned earlier, the QA system became possible because I was able to parse the content into structure data and assign hash to each paragraph. This is not a feature available in Current Wikipedia.
I wish I can share a real application that demonstrates this approach. But my prototype system is not prepared to handle big traffic. So I will screenshots of the system in action.
- Incomplete queries (“Obama birthplace” → “Where was Barack Obama born?”)
- Misspellings (“chernobyl accident deaths” → “How many people died in the Chernobyl disaster?”)
- Different phrasings (“France nuclear percentage” → “What percentage of France’s electricity comes from nuclear power?”)
Similarity scores consistently exceed 0.9, indicating very precise matching.
The increased vector store size—approximately tenfold due to question-based indexing rather than passage-based—remains manageable given modern vector databases’ capability to efficiently search billions of records. While Wikipedia’s frequent updates necessitate question regeneration, hash-based tracking enables selective re-indexing of modified passages only. The experimental implementation indexed under 1,000 Wikipedia articles, utilizing llama-3.1-8b-instruct-awq for question generation and baai/bge-small-en-v1.5 (384-dimensional vectors) for embeddings, with processing conducted as a background task.
Multimodal content (images, videos, 3D models) becomes searchable through question-based matching of their associated metadata. For instance, Wikidata triples like “Q243:P4896:[filename]” can be transformed into text (“Eiffel Tower: 3D Model: [filename]”) and indexed with questions like “What is the 3d model of Eiffel Tower?"—enabling matches with user queries such as “Show me Eiffel tower 3d model.” Similarly, Q140:P51:[audio file name] facilitates answers to queries like “How does the lion roar?”
Technical Advantages
The question-to-question approach offers several compelling technical benefits. First and foremost, it provides a zero-hallucination guarantee by completely eliminating LLM-generated responses at query time. Instead, the system directly retrieves original Wikipedia content, maintaining the authority and integrity of editor contributions while achieving remarkably high cosine similarity scores.
Computational efficiency represents another significant advantage, as the system requires no runtime LLM calls during inference, resulting in substantially lower query times and operating costs compared to traditional RAG systems, while still maintaining fast vector similarity search capabilities that scale effectively to millions of questions.
Additionally, the approach seamlessly supports multimodal content by handling text, images, and structured data through a unified question-based framework, enabling natural integration with Wikidata’s diverse content types and allowing users to reference multimedia elements through natural language queries.
Implementation Considerations
The system does require more storage than traditional RAG approaches, with approximately 10x increase in vector store size due to storing multiple questions per passage. This increased storage requirement is typically manageable with modern vector databases designed to efficiently handle billions of records. For handling Wikipedia’s frequent updates, the system employs selective re-indexing that tracks changes and only regenerates questions for modified content. The experimental implementation utilized LLaMA 3.1-8b-instruct-awq for question generation and BGE-small-en-v1.5 for creating 384-dimensional embeddings, with all index updates processed as background tasks to minimize disruption to the service.
Current Limitations
Despite its advantages, the system faces several notable limitations. While exceptionally effective for factoid questions, it struggles with complex multi-hop reasoning and has limited capabilities for data aggregation across multiple sources. Language support presents another challenge, as the system is currently optimized primarily for English, with varying degrees of effectiveness in other languages due to differences in both LLM availability and embedding quality across linguistic contexts. Content currency also requires careful management through periodic re-indexing processes that track Wikipedia changes and regenerate questions for modified content, adding operational complexity to maintaining an up-to-date knowledge base.
Evaluation Considerations
A key limitation of this exploration is the lack of formal evaluation against benchmark datasets. While extensive testing with diverse user queries has shown promising precision, a rigorous comparative assessment would provide more objective performance metrics.
Conclusion
This question-to-question retrieval approach offers a promising direction for Wikipedia question answering systems. By eliminating hallucination risk and improving retrieval precision, it provides a more reliable way to access encyclopedic knowledge. While there are limitations to address, the core approach demonstrates that sometimes rethinking the fundamental problem structure can lead to elegant solutions.
You may use this google collab notebook to try out the code snippets mentioned in this blog post: https://colab.research.google.com/drive/1o6rjV2AYCl9aR8xbMDcj91LVRU9VaN_3?usp=sharing
Disclaimer
I work at the Wikimedia Foundation. However, this project, exploration, and the opinions expressed are entirely my own and do not reflect my employer’s views. This is not an official Wikimedia Foundation project.
This is Part 5 of my exploration I was doing about building a natural language question answer system for wikipedia. See previous blogpost Part 4
Update(17-March-2025): I came across a paper titled “The Geometry of Queries: Query-Based Innovations in Retrieval-Augmented Generation” that explored the question generation and then comparing questions to questions for retrieval. The authors address healthcare domain. That paper, goes more depth in to the evaluation and comparison with traditional RAG systems.