Wikipedia, the world’s largest online encyclopedia, relies on a massive community of volunteers to maintain its accuracy and neutrality. But with so many editors, how do you ensure edits adhere to Wikipedia’s strict policies? I decided to explore whether Large Language Models (LLMs) could be used to automatically detect policy violations in Wikipedia edits. Here’s what I found.
Wikipedia has well-defined policies to ensure content quality. These include:
- WP:NPOV (Neutral Point of View): Avoiding bias and presenting information objectively.
- WP:NOR (Original Research): Preventing the inclusion of unsourced or synthesized claims.
- WP:PEACOCK (Promotional Language): Discouraging exaggerated or boastful language.
- WP:WEASEL (Weasel Words): Eliminating vague or unattributed statements.
- WP:BUZZ (Marketing Buzzwords): Avoiding trendy but meaningless jargon.
- WP:VANDALISM: Preventing malicious or destructive edits.
Manually reviewing every edit for these violations is what the reviewers do. But with the volume of edits on Wikipedia, this is a daunting task. Could LLMs help automate this process?
My goal was to build a system that could analyze a proposed Wikipedia edit and flag potential policy violations. Here’s how I approached it:
1. Formatting Edits for LLMs: Diffs that Make Sense
The standard “diff” format (showing insertions and deletions with markup) is difficult for both humans and LLMs to parse. So, I opted for a simpler approach:
- Instead of complex diffs, I presented the LLM with the “before” and “after” content of the edit. This made the comparison more natural and, I believe, closer to the kind of text data LLMs are trained on.
- I instructed the LLM to generate a one-line summary of the difference between the “before” and “after” content. This was intended to guide the LLM’s “thought process” before assessing policy violations.
Example:
Here is a sample edit based on a real Wikipedia edit:
'Fernando Botero Angulo''' (born April 19, 1932) is a Colombian [[figurative art]]
ist. is a <ins>[[</ins>painter<ins>]]</ins>, <ins>[[</ins>sculptor<ins>]]</ins> and
<ins>[[</ins>draftsman<ins>]]</ins>. World art icon, extensive work is recognized by
children and adults alike everywhere. It is considered living artist originally from
Latin America's most recognized and quoted the world.
You can see the <ins> tags in the diff. The text becomes harder to read, and the LLM has to parse the markup. Instead, I presented it as:
Before:
Fernando Botero Angulo (born April 19, 1932) is a Colombian figurative artist. He is
a painter, sculptor, and draftsman. His extensive work is recognized by children and
adults alike everywhere. He is considered a living artist originally from Latin
America's most recognized and quoted the world.
After:
Fernando Botero Angulo (born April 19, 1932) is a Colombian figurative artist. He is
a [[painter]], [[sculptor]], and [[draftsman]]. His extensive work is recognized by
children and adults alike everywhere. He is considered a living artist originally
from Latin America's most recognized and quoted the world.
This format is much easier for the LLM to understand. I also instructed the LLM to summarize the difference between the two texts in one line:
That summary was:
Added wiki links to painter, sculptor, and draftsman.
This summary is not only easier for the LLM to process, but it also provides a clear context for the subsequent policy violation assessment. `
2. Prompt Engineering
I spent significant time crafting effective prompts. This included:
- Simplifying and Rewriting Policies: I reworded the Wikipedia policy definitions for clarity and conciseness.
- Explicit Output Formatting: I provided clear instructions on the desired output format to ensure the responses could be easily parsed.
- Few-Shot Prompting: I included several examples of edits and their corresponding violation assessments in the system prompt to guide the LLM.
For example, I changed the narrative from “These are guidelines, find violations” to explicit violation statements.
From:
Wikipedia Policy Definitions:
1. WP:NPOV (Neutral Point of View):
- Detect bias, promotional language, or subjective statements
- Ensure information is presented objectively
- Identify statements that present opinions as facts
- Check for balanced representation of views
To:
1. WP:NPOV - Violation of Neutral Point of View:
- Inserting personal opinions or biased language
- Presenting subjective statements as objective facts
- Using loaded or emotionally charged descriptors
- Disproportionately representing one perspective
3. Testing with Real Wikipedia Edits
Initially, I used made-up examples to test the system. But when I switched to real-world edits fetched directly from English wikipedia using revision IDs, things got interesting.
- Wikitext Sensitivity: The LLM was initially overly sensitive to Wikitext formatting, sometimes flagging it as vandalism. Insertion of complex template syntax was considered as vandalism.
- False Positives: Many good-faith edits were incorrectly flagged as violations.
To address this, I made further prompt improvements. I avoided the broad instruction of “Assume good faith” as it was hard to control. Instead, I added specific instructions, like “Adding categories or templates, and bookkeeping activities like… are not violations” to reduce false positives.
As with any prompt engineering, it was a process of trial and error.
4. Implementation
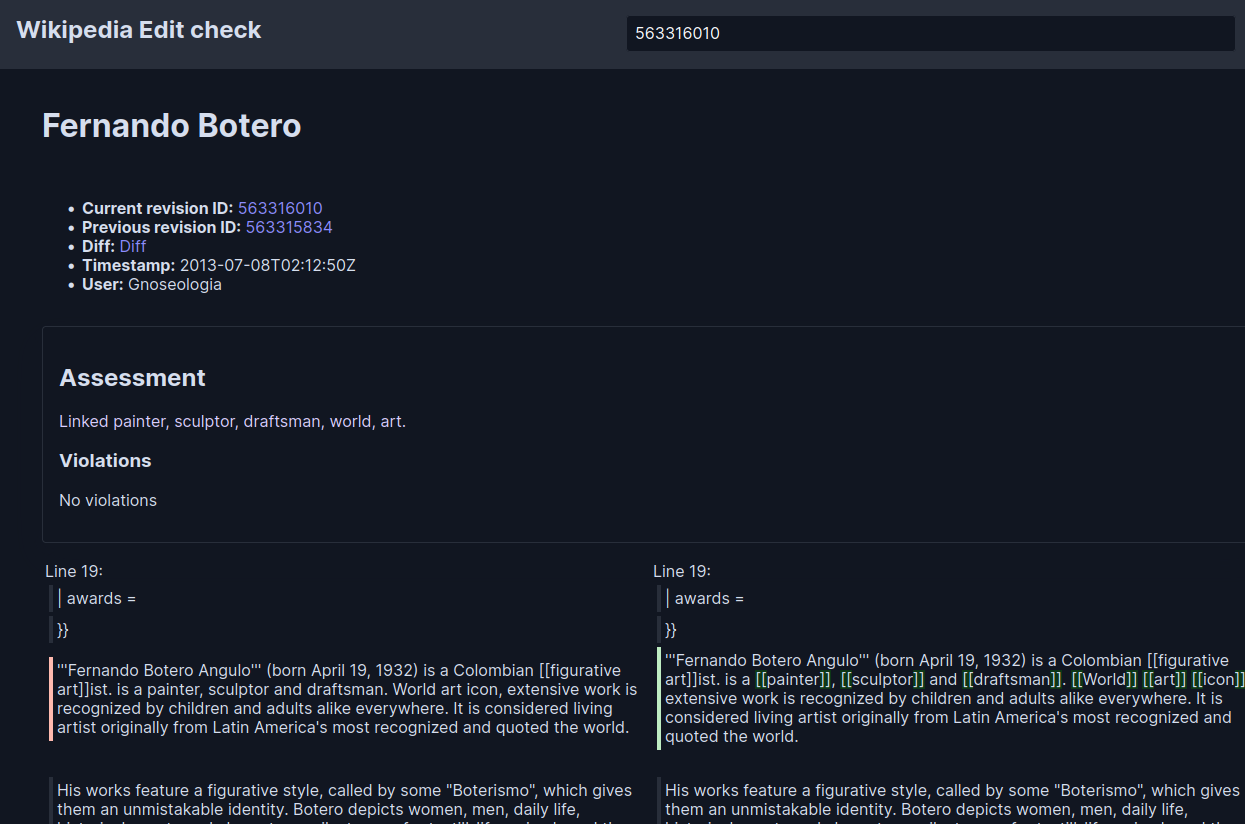
In the following screenshot, I am checking revision https://en.wikipedia.org/wiki/Fernando_Botero?oldid=563316010 from the Fernando_Botero article. As you can see, the LLM correctly identified the edit does not violate any policies. You can test this by visiting the tool https://editcheck-llm.toolforge.org/?revision=563316010
In the next screenshot, I am checking revision https://en.wikipedia.org/w/index.php?oldid=843673669 from the Moana (2016 film) article. The LLM identified that the edit violates WP:PEACOCK and WP:NPOV policy. You can test this by visiting the tool https://editcheck-llm.toolforge.org/?revision=843673669
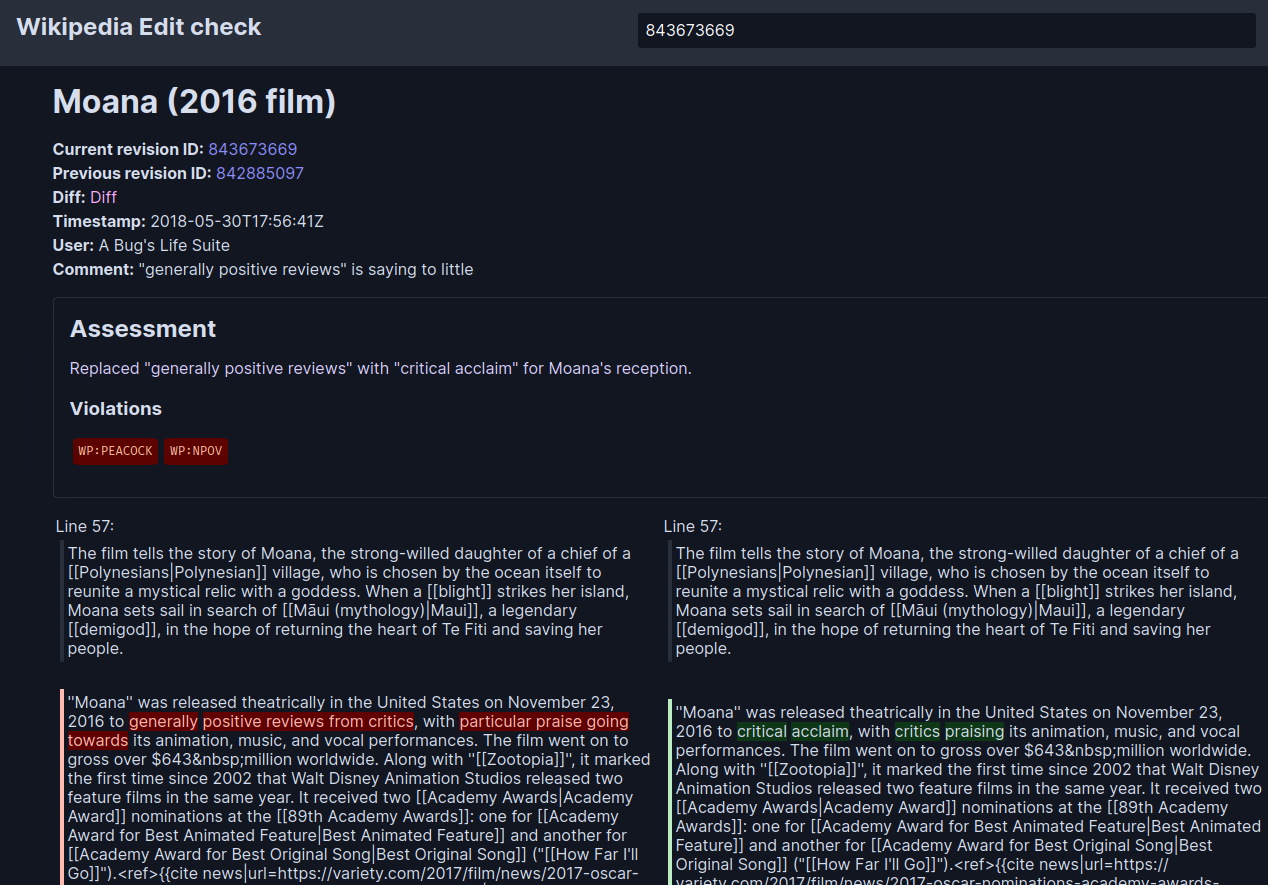
Was it really a violation? The edit replaced “generally positive reviews” with “critical acclaim” for Moana’s reception. We can check the accuracy of this claim by looking at the article’s further edits. In the next revision (843676200), the edit was reverted, and the original text was restored. This suggests that the LLM’s assessment was correct. Yay!
That was a tough edit to assess, and the LLM did a good job. Following examples are easier to assess, and the LLM did a good job too. Potentially, the system would be saving valuable time for the reviewers.
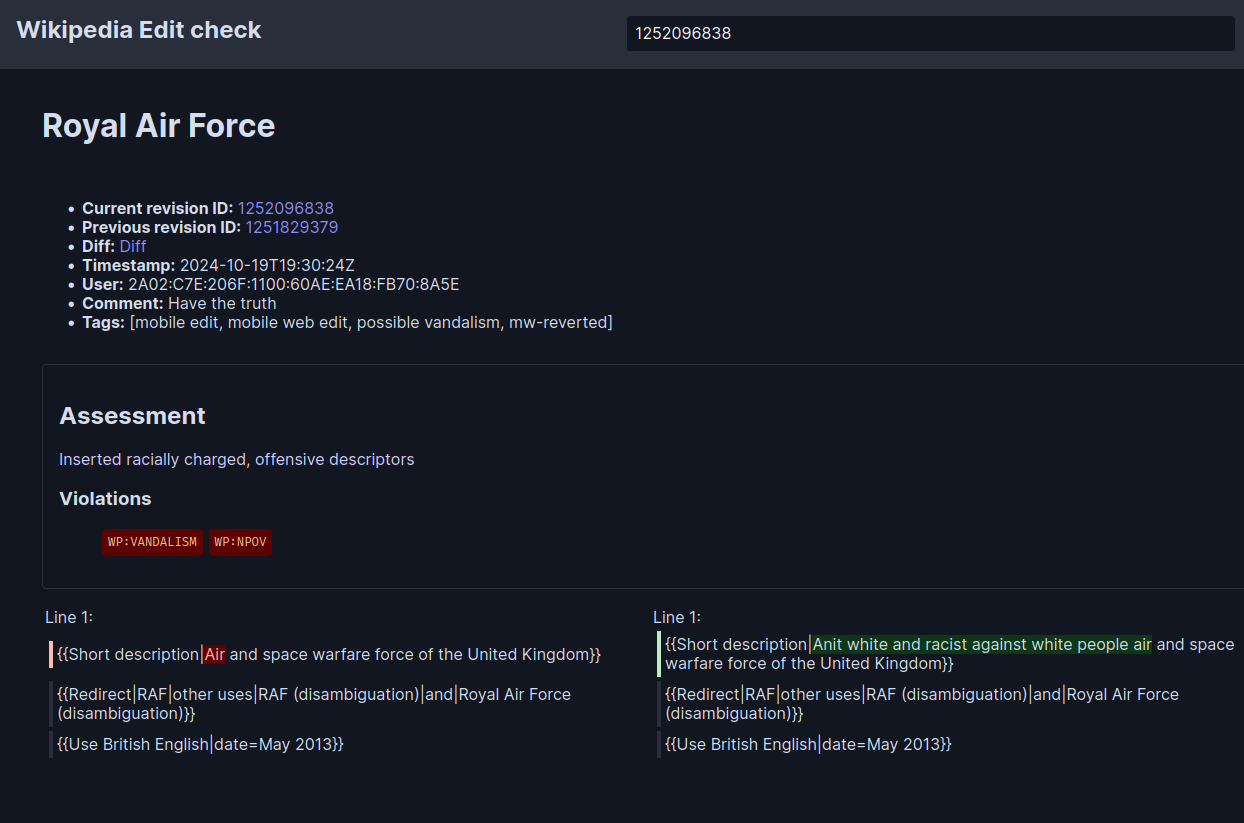
Another one:
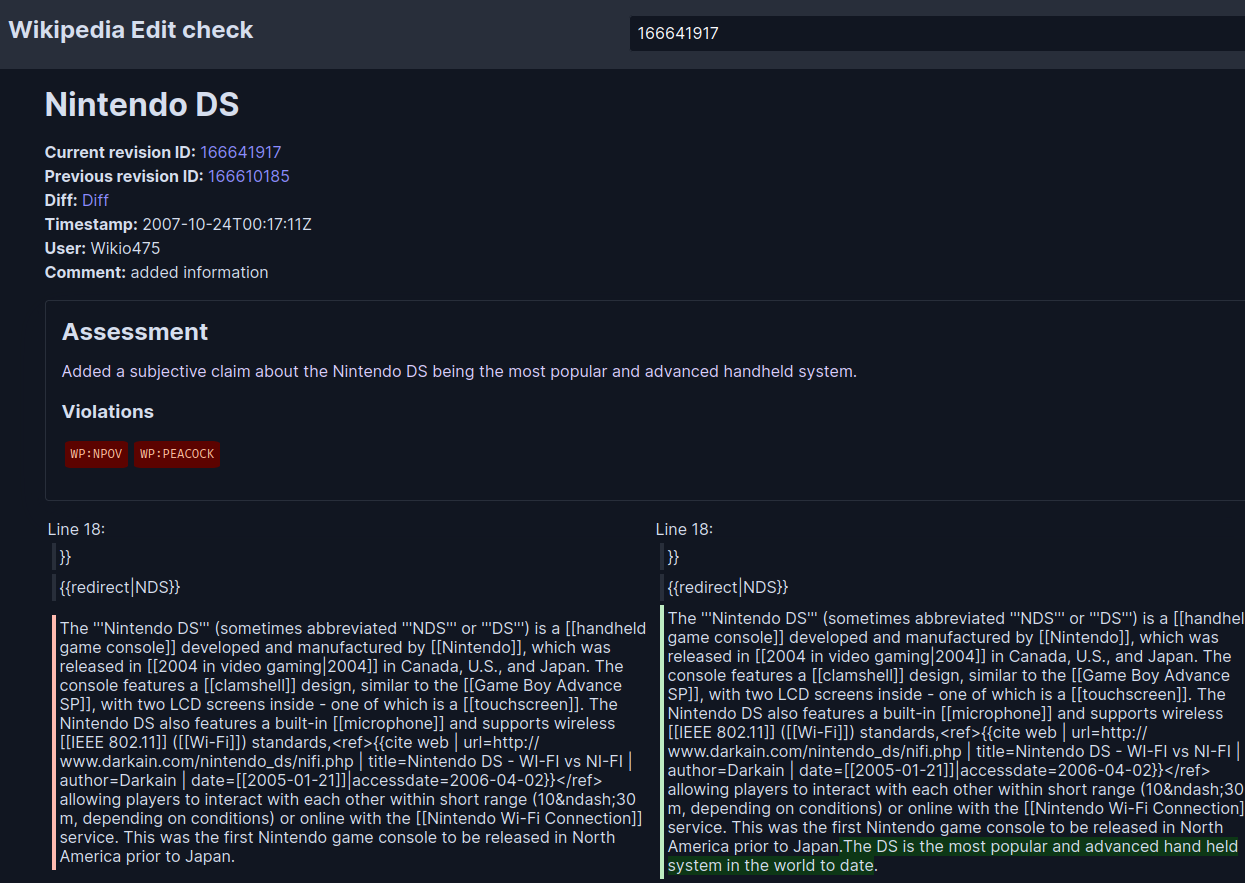
The program is written in Rust for performance and reliability. I used the Gemini API for LLM access, but the code is designed to be modular, allowing for easy integration with other LLMs in the future.
- Link to the tool: https://editcheck-llm.toolforge.org
- Source code: https://gitlab.wikimedia.org/toolforge-repos/editcheck-llm
- Prompt: https://gitlab.wikimedia.org/toolforge-repos/editcheck-llm/-/blob/master/src/prompts.rs?ref_type=heads
Results and Challenges
The experiment showed promise, but also highlighted key challenges:
- Sensitivity vs. Accuracy: Balancing the LLM’s sensitivity to potential violations with the need to avoid false positives is crucial.
- Context is important: The LLM needs more context to make accurate assessments. Future work could incorporate the editor’s history of contributions, roles, edit summaries as inputs.
Future Directions
Here are some ideas for future development:
- Hybrid Approach: Combining LLM analysis with heuristics based on user reputation (anonymous or not, contribution count, registration date, roles) to improve accuracy.
- Real-time Feedback: Ideally, these checks should happen before the user saves the edit, providing real-time nudges to encourage policy compliance.
- Multilingual Support: Expanding the system to support more languages will require careful consideration of model performance and cost. I used Gemini API for this experiment, but other models might be better suited for different languages.
Product Considerations: Precision is Paramount
From a product perspective, it’s critical to minimize false positives. A system that incorrectly accuses editors of policy violations will quickly lose credibility.
- Prioritize Precision: It’s better to miss a violation than to incorrectly flag a legitimate edit. In terms of precision and recall, we should optimize for high precision, even if it means lower recall.
- Positive Nudges: Presenting feedback in a positive and constructive way is essential for encouraging compliance. Instead of saying “This violates WP:NPOV,” the system could say, “Consider rephrasing this to ensure a neutral point of view.”
Conclusion
This experiment demonstrates the potential of LLMs to assist in maintaining the quality and neutrality of Wikipedia. While challenges remain, ongoing improvements in LLM technology and prompt engineering could lead to powerful tools that support Wikipedia’s mission for free and accurate knowledge.
Disclaimer
I work at the Wikimedia Foundation. However, this project, exploration, and the opinions expressed are entirely my own and do not reflect my employer’s views. This is not an official Wikimedia Foundation project.
For Wikimedia Foundation’s official initiative related to this, please refer https://en.wikipedia.org/wiki/Wikipedia:Edit_check and https://phabricator.wikimedia.org/T265163