I wrote about the exploration on Natural language querying for wikipedia in previous three blog posts.
In Part 1, I was suggesting that building such a collection of question and answers can help natural language answering. One missing piece was actually suggesting an answer for a new question that is not part of QA set for article.
In Part 2, I tried using distilbert-base-cased-distilled-squad with ONNX optimization to answer the questions. I used a hybrid approach of Named Entity recognition on the question to find relevant titles. I also feed this question to Wikipedia search api and extract the titles returned by it. The results were not optimal. The answers were just a word or phrase. If that is found in the retrieved context. Context retrieval based on NER or Wikipedia search was also not giving related wikipedia articles.
In Part 3 I wrote about experiment with the Retrieval Augmented Generation approach. RAG require a Large Language Model at the last step to prepare the answer. I also wanted this to be highly compute optimized so that it can run on CPUs. I prototyped a compute optimized RAG with an LLM to present the answers. I learned many lessons after trying out many examples with the system and refined my approach. In this blog post I will explain the new approach.
Background
One significant concern I had with the RAG (Retrieval-Augmented Generation) approach was its reliance on Large Language Models (LLM). In this approach, LLM is used in the final step to formulate an answer based on the retrieved context. However, this articulation process lacked control and predictability. It often added common adjectives to facts, even when such descriptors were not present in the retrieved context. This resulted in the need for extensive fine-tuning of prompts, which goes against the debugging and bug-fixing paradigm I’m familiar with.
Additionally, the language capabilities of LLMs posed another constraint, and the computational requirements were also a concern. When I considered this behavior of the RAG approach in light of Wikipedia principles, I discovered several mismatches. These included issues related to transparency, the inability to correct answers, and more.
To address these concerns, I delved into the field of information retrieval and user expectations from search systems. In my research, I came across two important studies authored by Emily Bender and Chirag Shah:
- Situating Search
- Envisioning Information Access Systems: What Makes for Good Tools and a Healthy Web?
These papers shed light on the nature of search, its significance in a user’s learning and exploration workflow, and various techno-social aspects. They also discuss issues such as bias, transparency, and explainability. I highly recommend reading these papers if you are involved in information retrieval.
Furthermore, I explored various papers related to RAG-based and general information retrieval. Notably, the ACL 2023 Tutorial: Retrieval-based Language Models and Applications. Also, Building Scalable, Explainable, and Adaptive NLP Models with Retrieval by Omar Khattab, Christopher Potts, and Matei Zaharia in Stanford AI Lab Blog. The summary section of this article was particularly intriguing.
Summary: Is retrieval “all you need”?
The black-box nature of large language models like T5 and GPT-3 makes them inefficient to train and deploy, opaque in their knowledge representations and in backing their claims with provenance, and static in facing a constantly evolving world and diverse downstream contexts. This post explores retrieval-based NLP, where models retrieve information pertinent to solving their tasks from a plugged-in text corpus. This paradigm allows NLP models to leverage the representational strengths of language models, while needing much smaller architectures, offering transparent provenance for claims, and enabling efficient updates and adaptation.
Imagine if we zero in on the retrieval part of RAG without involving LLM in generating answers. What insights can we gain from retrieving information for natural language questions in Wikipedia? What limitations do we encounter, and how can we address them? These are the questions I set out to explore.
Approach
I wanted to build a more realistic knowledge base with semantic information compared to my previous attempt, where I only used 500 popular articles. However, creating a vector store for all ~7 billion articles in English Wikipedia is a costly endeavor, involving storage and computational expenses. Some individuals have tried this before, as mentioned in this tweet. Additionally, I wanted to test the efficiency of updates, particularly how well the system handles updates when new edits are made.
But why go through the trouble of preparing the entire Wikipedia vector store when we can generate embeddings on-demand? The embedding system I’m using is the e5-small-v2 model, optimized with ONNX. I found that it can generate embeddings for a Wikipedia page in under a second in most cases. So, I decided to start with the vector store containing the 1000 most popular articles from English Wikipedia. These articles are quite lengthy and may take more time for embedding. In the retrieval process, if there’s no match in the vector store, the system performs a search in Wikipedia, identifies relevant articles, generates embeddings for them, and then adds them to the vector store. After that, it re-runs the search.
This approach immediately empowers the QA system to search within the entire English Wikipedia.
In previous approach, I was using Chroma Vector store for vector store, but since Redis latest versions has KNN Vector search available, I chose Redis because it’s a well-tested and familiar database system.
Embedding model
In my search for an embedder that can work beyond English, I found E5 model - based on “Text Embeddings by Weakly-Supervised Contrastive Pre-training.” paper. The largest variant of this model - Multilingual-E5-large - claim to support around 100 languages. However, I used the smallest e5-base-v2 model for my experiment as I don’t have the compute capacity for bigger model. Even e5-base-v2 model required onnx optimization to run fast enough in CPUs.
The Telegram Bot
I tried to create a telegram chat bot that provides a friendly chat interface for the questions, returns the results with a context from wikipedia that can answer the question, an article preview and link to article.
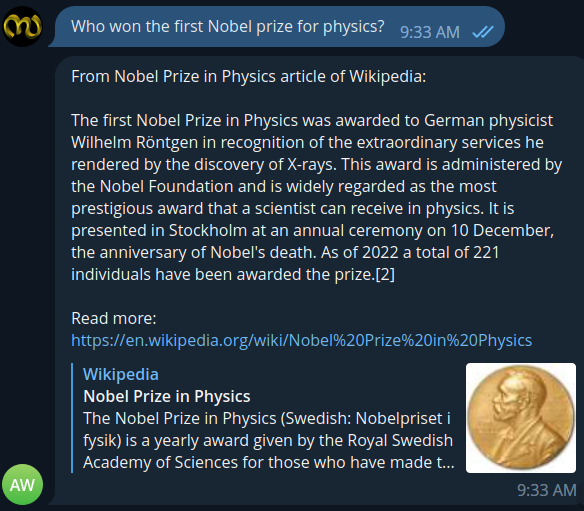
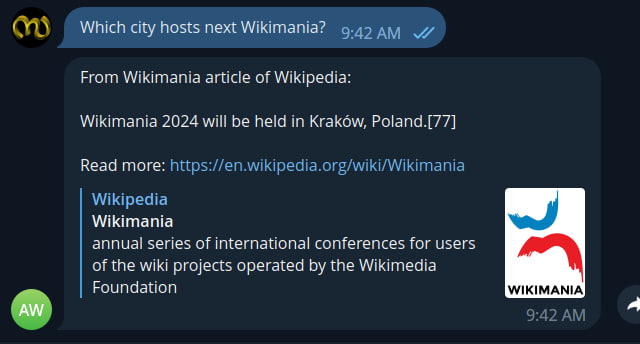
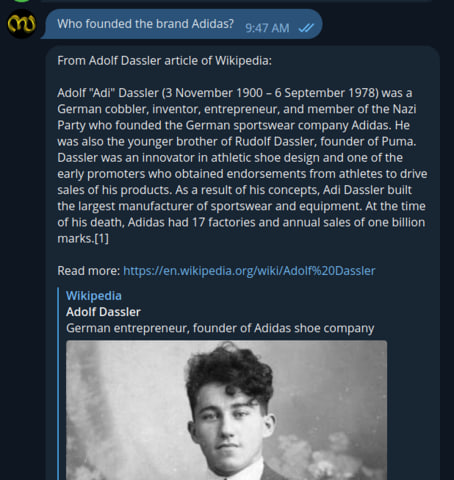
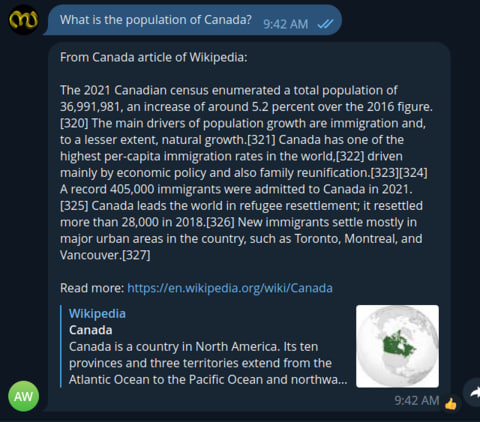

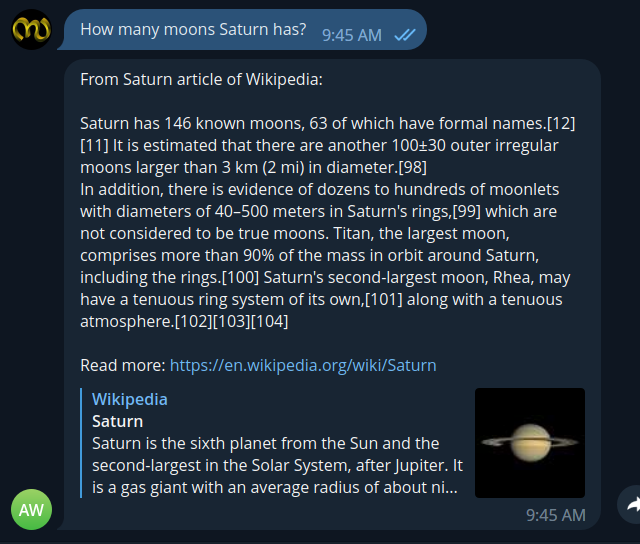
I am not sharing the link of telegram bot here since I cannot run it infinitely and not built for wider usage. However, ping me if you need a link for quick testing.
Source code
Source code: https://github.com/santhoshtr/wq
Lessons
The examples I shared earlier clearly demonstrate that when compared to a direct Google search and Wikipedia’s search function, semantic searching within Wikipedia content is a significant improvement over the current experience. It’s definitely a superior approach compared to the existing keyword-based search in Wikipedia.
For our prototype, using on-demand embedding suffices, but it may not be adequate for a production scenario. There are a couple of reasons for this. Firstly, the quality of the articles returned from a search query directly relies on the effectiveness of Wikipedia’s keyword-based search, which I found to have several shortcomings. Secondly, the time it takes to generate embeddings may be much longer than what I observed in my experiment, as explained below.
In my experiment, I used a chunking strategy where I treated each paragraph in an article as individual units for embedding. Depending on the length of the paragraph, its content might not fit within the maximum input size of the embedding model. When it doesn’t fit, the default behavior is to clip the content, meaning that some of the last sentences from paragraphs will be ignored. This is not an acceptable outcome. On the other hand, if we use a single sentence at a time for embedding, it introduces its own set of issues. The time required for embedding and vector storage becomes longer, but more critically, it leads to a loss of semantic context.
I encountered an important question: What makes up an ideal, independent, and complete semantic context for embedding? For instance, if two sentences together hold the answer to a question in terms of vector similarity, it’s crucial to embed them together to ensure accurate retrieval. But how can we determine this? One approach could be assuming that a paragraph represents a semantically complete unit, containing a full information context.
We might consider using a sliding window strategy to prevent the loss of context. For example, if we have sentences s1, s2, and s3, we could embed combinations like s1+s2, s2+s3, s3+s4, and so on. There are also techniques like hierarchical embedding, where the similarity score of the entire paragraph embedding is used in conjunction with individual sentences. For instance, if we find that s2 is similar to the query, and s3 is also similar to the query, we can check if they are similar to the cluster of sentences around s1 and s3, and then retrieve that context.
Another challenge is that section titles are often not embedded along with paragraphs. For example, if there’s a section titled “Plot” followed by a paragraph detailing the plot of a movie, embedding the section title and paragraph separately makes it difficult to answer questions like “What is the plot of this movie X?” One potential solution is to prefix the section title with the paragraph or sentence while embedding. Sometimes, we might also need to prefix the article title.
The paper I linked in the beginning of article illustrats the issue of context split with this example.

Additionally, retaining the content from tables, lists, and infoboxes presents its own challenges. How do we preserve the semantic context in a vector embedding for a table? For instance, in a table listing Olympic winners, how can we retrieve an answer to “Who won the most medals?” These are complex issues that require thoughtful solutions.
I also conducted some testing with non-English languages, including Malayalam, my native language. I noticed that the vector similarity approach isn’t as effective in non-English languages as it is in English. This can be attributed to the limited resources and training data available for these languages. However, the language’s typology also plays a role. Malayalam is a morphologically rich language with productive agglutination and inflection. In such languages, the number of tokens are relatively higher than English which can lead to sparse vector space and less effective clustering. We need to conduct more experiments to better understand the multilingual aspect of this technology.
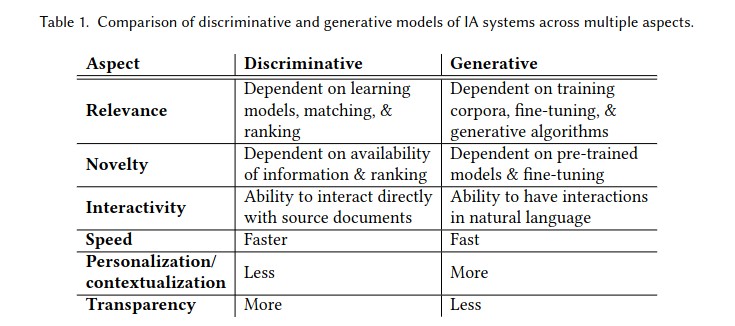
In my personal view, Wikipedia’s approach to question-answering should go beyond providing a single sentence answer without further context on how the answer was obtained, what assumptions were made, who authored it, and how to make corrections. A more effective approach would involve responding to a question with a retrieved context from a Wikipedia article, along with links for further exploration. This approach eliminates the need for probabilistic, black-box algorithms between the user and the knowledge base. Emily Bender and Chirag Shah refer to these approaches as “Generative” and “Discriminative,” respectively. Moreover, presenting context invites users to delve deeper, refine their questions, and discover new facts.
Disclaimers
- This is just a prototype of a concept and does not discard all product design and community interaction efforts that need to happen, in case this becomes reality one day. I am curious to hear various prospects, product design ideas you may have.
- There are many important considerations that I omitted for simplicity in this prototype.
- I work at Wikimedia Foundation. However, this proposal and opinions are my personal views and does not reflect my employers view.
Have fun!