A few days back I posted an experiment on Natural language querying for wikipedia by generating questions and answers. I was suggesting that building such a collection of question and answers can help natural language answering. One missing piece was actually suggesting an answer for a new question that is not part of QA set for article.
As a continuation of that experiment, I was exploring various options for answering questions. I used the following approach:
- For the question, find the relevant articles. I used a hybrid approach of Named Entity recognition on the question to find relevant titles. I also feed this question to Wikipedia search api and extract the titles returned by it.
- The content of these articles will be fed into BERT model optimized for QA. I used distilbert-base-cased-distilled-squad by huggingface which is trainined on SQuaD dataset. Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. It is only for English. So we definitely have a serious constraint here.
- DistillBERT cannot run on CPUs as such, so I optimised it using ONNX runtime.
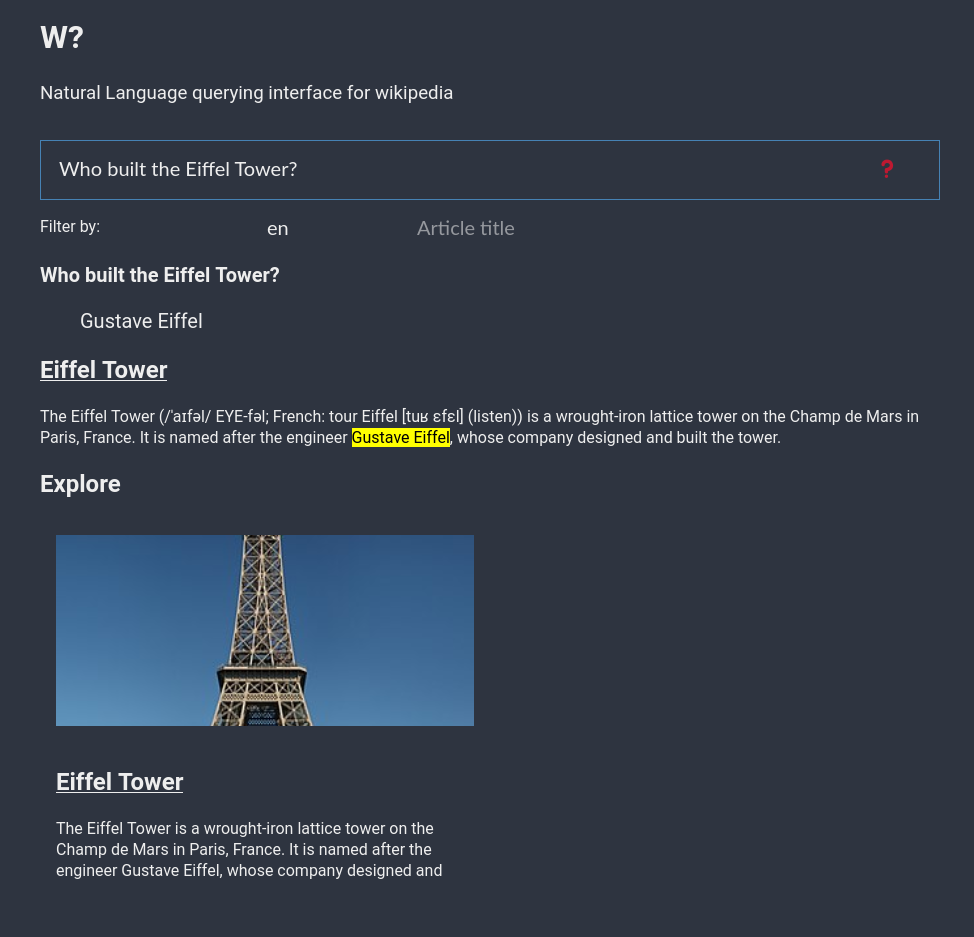
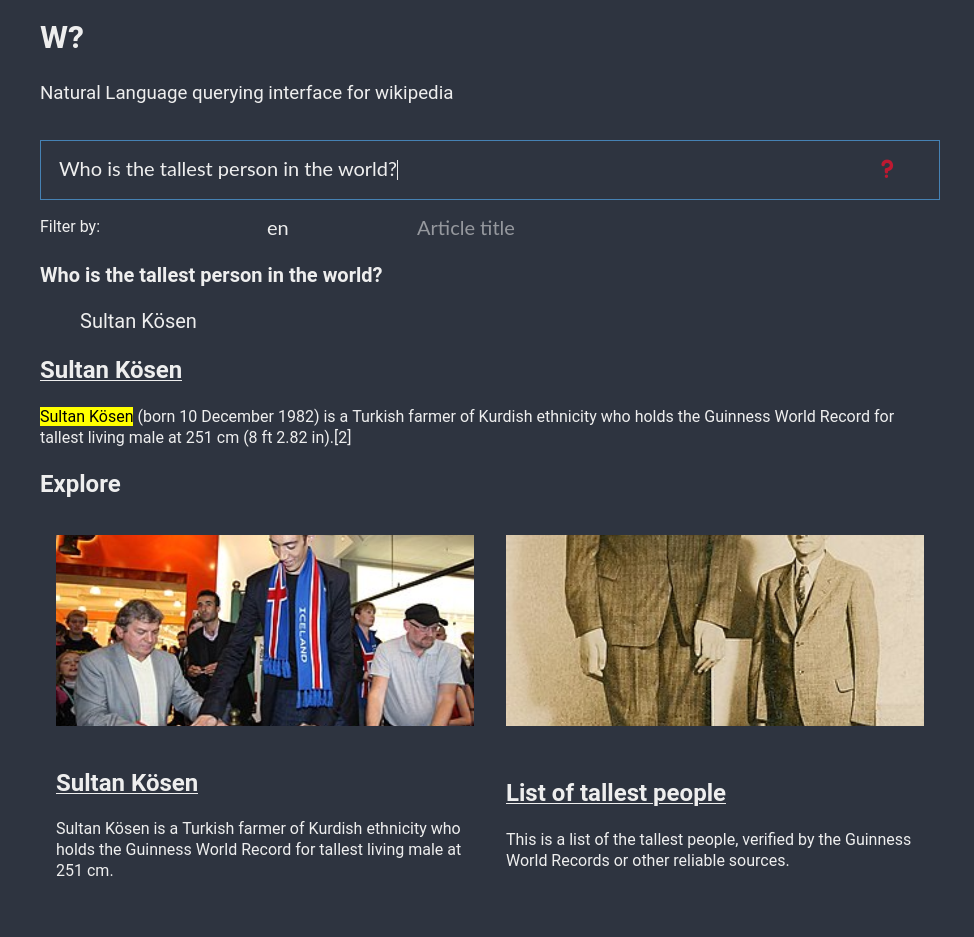
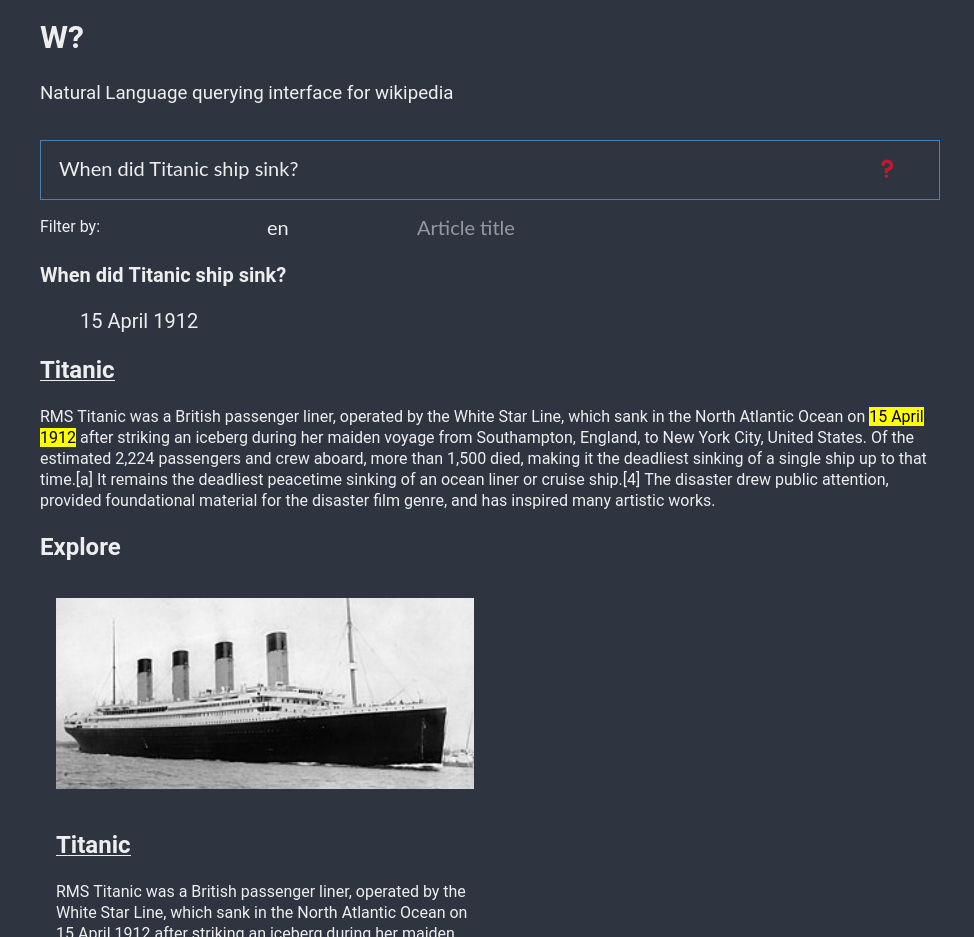
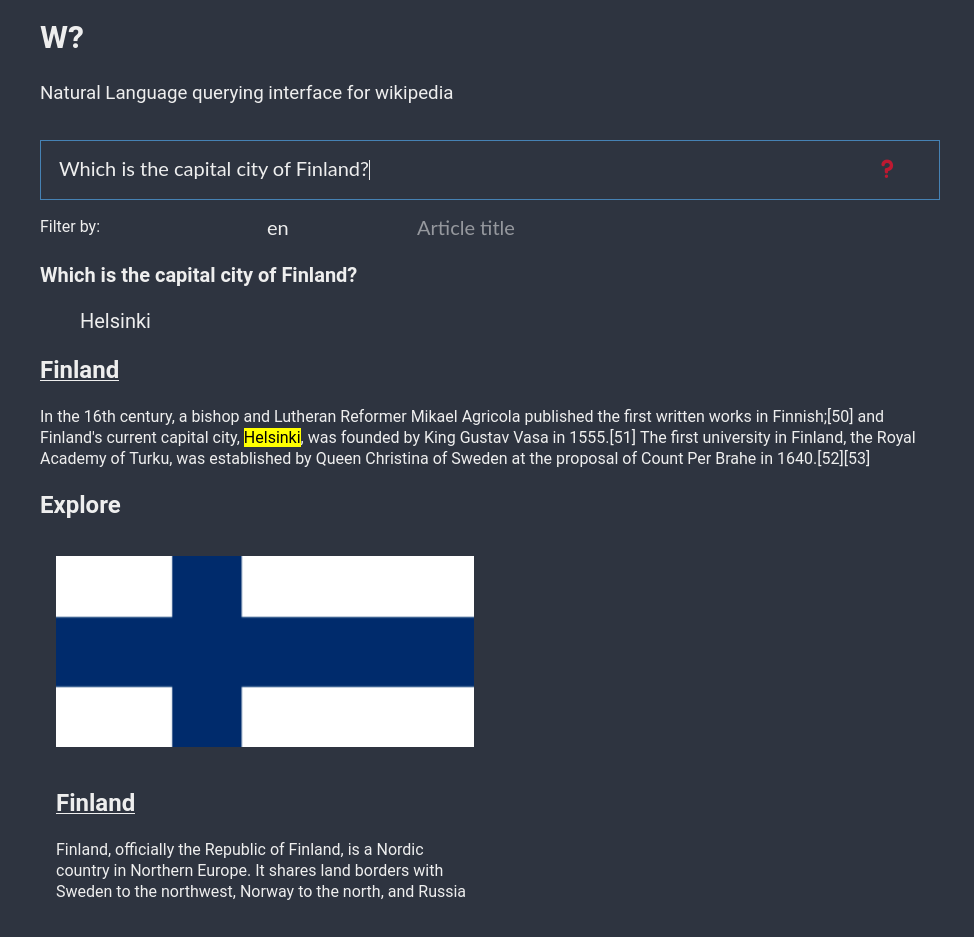
- Set a high threshold for the QA pipeline scores, once the answer is retrieved, the part of the article where the answer is found is retrieved and highlighted. This is important to show to users to tell how this particular answer was found.
- Along with answer, the articles used for answer extraction is also present to users for further exploration.
- The whole system was slow, so did some redis caching to make it fast.
Demo at https://wq.thottingal.in/.
Code at https://github.com/santhoshtr/wq