In this blog post I explain the prospects of providing questions and answers as an additional content format in wikipedia and a human-in-the-loop approach for that with a prototype.
Introduction
Wikipedia is a hub for curiosity, with people visiting the site in search of answers to their questions. However, they typically arrive at Wikipedia via intermediaries such as search engines, which direct them to the relevant article. While Wikipedia’s keyword-based search function can be helpful, it may not be sufficient for addressing more complex natural language queries. As a result, AI-based conversational agents like ChatGPT have become increasingly popular for knowledge seekers. However, the accuracy and reliability of information provided by AI systems may be questionable.
To address this issue, there is a need for a reliable and verifiable source of information that can be queried using natural language questions. Wikipedia’s editor community has created the largest encyclopedia in the world, making it an invaluable resource for natural language queries. However, providing an AI-based solution to answer all questions based on Wikipedia content may not align with Wikipedia’s principles and practices.
In the current state of natural language processing, the straight forward solution that will come to our mind would be to provide an AI based solution that answer all questions based on Wikipedia content. Baring all technical challenges, let us just assume, we build such a solution. For me, this approach does not go very well with the wikipedia’s principles and practices. Why?
One major concern is that such a system may provide probabilistic answers that contain false information, even if the correct information is present in Wikipedia content. This was tested by a colleague at the Wikimedia Foundation, who provided a Wikipedia article to ChatGPT and asked it questions. Another issue is that the content in Wikipedia is always editable, but the answers provided by AI systems are not. They are output from a black box and cannot be explained, nor are they human-approved.
Furthermore, providing a question-answering system that adheres to Wikipedia’s principles requires supporting the site’s 300+ languages.
Finding a solution that uses the language capabilities of current large language models while still adhering to Wikipedia’s principles is an interesting challenge.
Proposed solution
Let us have a new content format associated with every article: “Questions”. This would be very similar to current Talk namespace where people have discussions about article. The Questions namespace will have all possible questions related to article content and answers. People canedit the questions, answers. People can ask questions and others can answer it. The answers can have everything a wikipedia article can have - references, images etc. Every Question answer unit can have its own revision, and edit workflows like reverts and vandalism checks.
You might be thinking that this is asking for a manual effort by editors to have all these possible questions and answers created, while they already spent their valuable time in editing the article content and content here are repetitions of same in different format.
But what if, if we can generate all these questions using a large language model and then humans just verify them and publish? Wikipedia has article translation tool that already use this human-in-loop method - translations for section are provided by machine translation engines and editors verify or edit it before it actually get published. Translator can also discard, or not use the translation proposal by machine translation engines and write their own translation from scratch. We can apply the same principle here.
However, I already mentioned that LLM’s answers are not completely reliable when article content is provided and then questions are asked on it. I found a solution for this problem by inverting the steps. Instead of asking a question based on the content, I asked the LLM to generate all possible questions from the content and give answers to it. This makes sure that answers are always extracts from the article content(It is rephrased as answer to a question) and questions are generated by LLM. From my experiments, I could not find any issues of hallucination. Here is the prompt I used with gpt-3.5-turbo model
Act as if no information exists in the universe other than what is in this text:
(wiki article text goes here)
Provide all possible questions and answers in json format with "question" and "answer" as keys.
I asked for json format just to avoid parsing plain text output from the model. It did provide json, but sometimes as array of questions answers, sometimes with a top level key ‘questions’ and value as array of questions and answers. Found it unpredictable, but it was not difficult to detect the format of json and act accordingly
Prototype
To illustrate the concept, I build a prototype. To capture the generated questions and answers and expose it as API, I wrote a server application. Source code: https://github.com/santhoshtr/wq and it has a simple web interface that runs at https://wq.thottingal.in. Note that this use the gpt-3.5-turbo API by OpenAI and I don’t promise it will run all the time. I will at least keep it running till I use up free API credit I received.
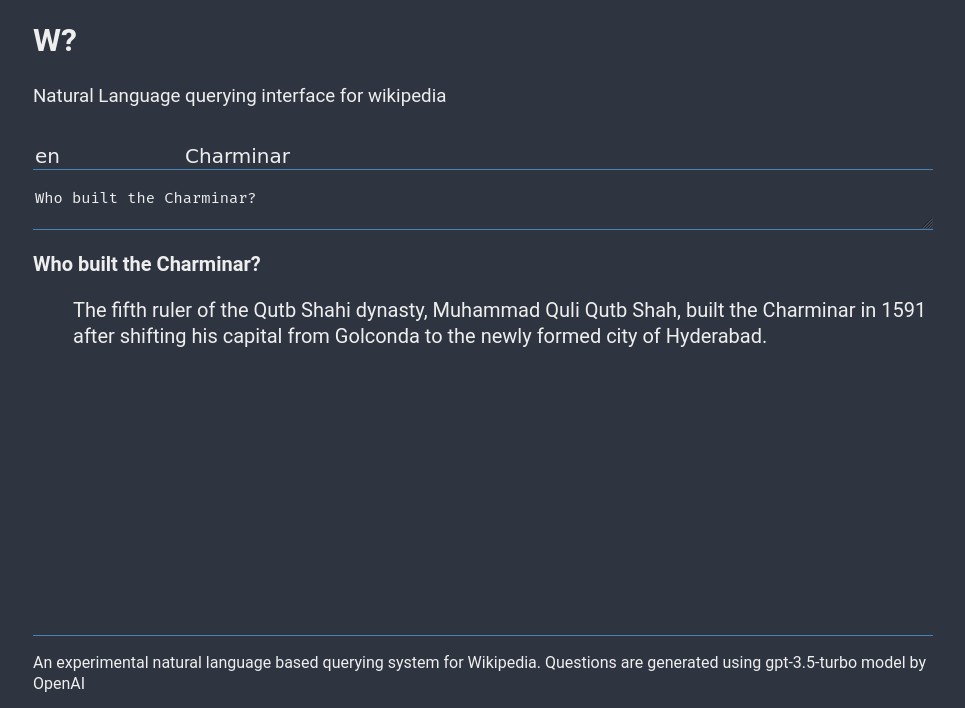
Then I integrated the API to Wikipedia articles using a simple userscript
And here is a video that showing “Questions” namespace listing all questions, allowing edit and adding questions.
Prospects
- The human-in-the-loop approach of having questions and answers is as per Wikipedia’s principles. This approach does not expose the results of an AI tool to readers without human approval. At the same time, the usage of LLM here saves manual effort and relies editors only for validations.
- Allowing people to ask questions opens up new ways of engagement and contributions.
- We are not limited by the languages supported by LLM as smaller languages can build the questions and answers list with the help of translation tool(that also require human validation). The proposed approach provides adding question and answer manually without relying on any tool.
- Enhancements like voting or methods to find most useful questions can become “Frequently asked questions” for the article
- Other content formats can be phrased as question and can be served by same system. For example, a summary of a large Wikipedia article is “Please provide a summary of this article” question. Also, we can have a question: “Explain this like I am 5 year old”
- Exposing the questions and answers through internal search engine is first step towards natural language querying. External search engines will also index them.
- For a question asked by a user, another user can add an answer. But here also, there are some emerging technologies that can provide a candidate answer and ask for human validation and publishing. Extending a LLM with a custom vector embedding and basing the QA on that is possible. For further reading: (a) Retrieval Enhanced Generative Question Answering with Pinecone (b) LlamaIndex llama (GPT Index) (c) Question Answering using Embeddings
Disclaimers
- This is just a prototype of a concept and does not discard all product design and community interaction efforts that need to happen, in case this becomes reality one day. I am curious to hear various prospects, product design ideas you may have.
- There are many important considerations that I omitted for simplicity in this prototype. For example, the dynamic nature of wikipedia articles and need for updating the question list. Using OpenAI’s proprietary model may not be the best choice as we may want to find open source large language models.
- I work at Wikimedia Foundation. However, this proposal and approach are my personal views and does not reflect my employers view. I had written and shared most of this concepts in 2019 in a document to my colleagues and it had this note: “Later we amend the system with machine generated questions and answers as well.” :-)
Have fun!