Integrating Knowledge Graphs (KGs) with Large Language Models (LLMs) is a well-explored research field. KGs are vast, structured databases storing factual associations as graph edges. KGs can help LLMs for tasks like question answering, drawing on the structured, often up-to-date information within KGs, thereby mitigating the risk of hallucination. For instance, an LLM that can query Wikidata—a prominent KG project—instead of solely depending on its training data becomes significantly more reliable and useful.
The paper “Large Language Models, Knowledge Graphs and Search Engines: A Crossroads for Answering Users’ Questions,” co-authored by Wikidata founder Denny Vrandečić, introduces a taxonomy of user information needs, guiding the exploration of the pros, cons, and potential synergies between LLMs, KGs, and Search Engines. The authors argue that these technologies are complementary, and integrating them allows the strengths of one to compensate for the weaknesses of others.
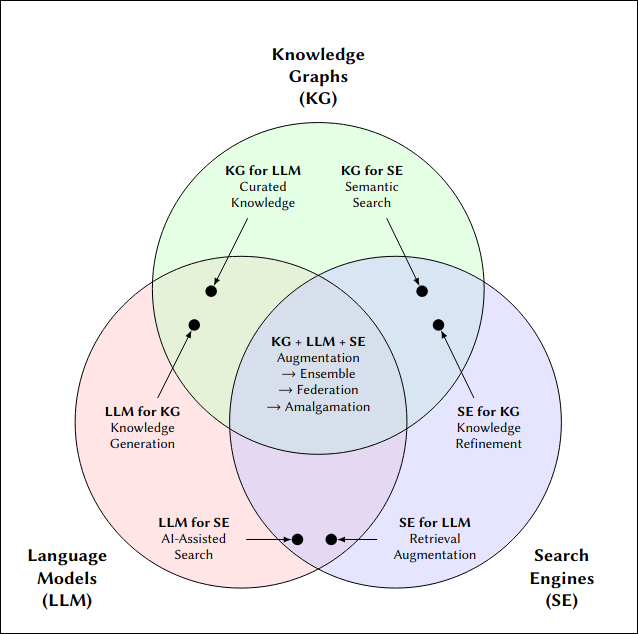 (Image credits: Large Language Models, Knowledge Graphs and Search Engines: A Crossroads for Answering Users’ Questions)
(Image credits: Large Language Models, Knowledge Graphs and Search Engines: A Crossroads for Answering Users’ Questions)
A wealth of published research explores various approaches for integrating KGs with LLMs. While an exhaustive list is beyond our scope, let’s touch upon a few key strategies:
-
Textualize KGs into formats like JSON, plain text, Markdown, or even custom structures. Embed these textual representations using vector embedding techniques. For tasks like question answering, employ Retrieval Augmented Generation (RAG). Typically, this involves injecting the retrieved (and textualized) KG data into an LLM’s prompt at a later stage. Hence, these are often termed prompt-based methods. The LLM itself isn’t typically trained or fine-tuned directly with the KG in this approach.
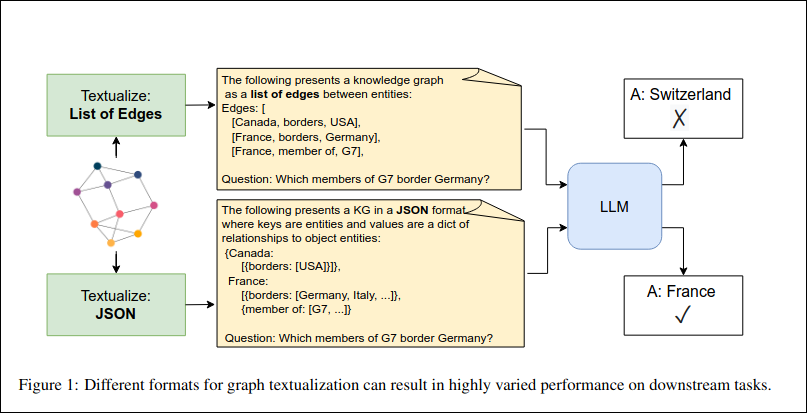
(Image credits: https://knowledge-nlp.github.io/naacl2025/papers/39.pdf)
-
Parameterized or Model-Integrated KGs: Here, the LLM is fine-tuned with KG data. One example is KG-Adapter, a parameter-level KG integration method leveraging parameter-efficient fine-tuning (PEFT). Another intriguing example comes from “Injecting Knowledge Graphs into Large Language Models.” This research integrates graph embeddings as tokens within the LLM’s input, extending the paradigm to the KG domain by leveraging Knowledge Graph Embedding (KGE) models.
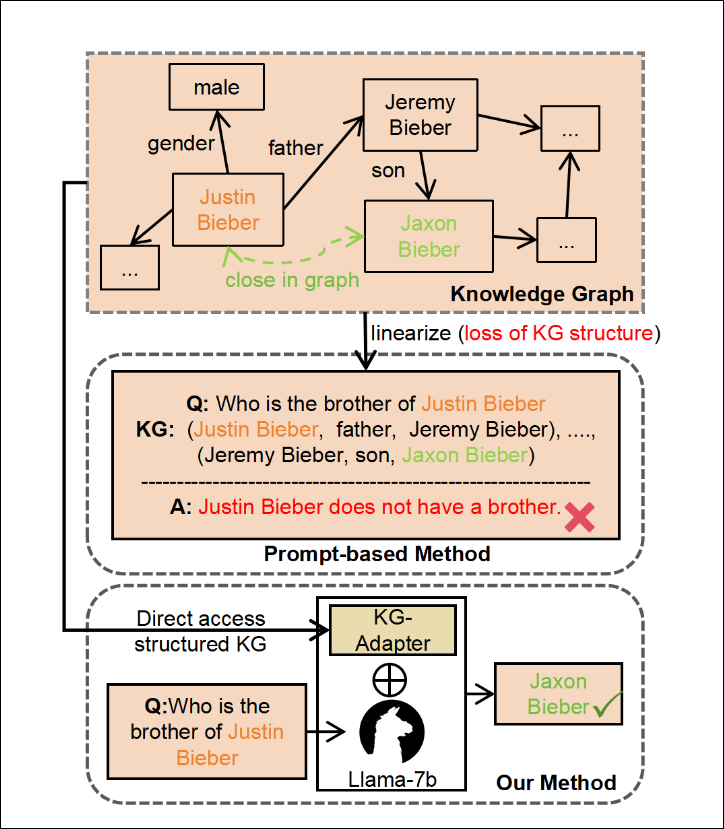
(Image credits: https://aclanthology.org/2024.findings-acl.229.pdf)
Both approaches—preparing embedding models for RAG or fine-tuning LLMs—demand significant effort, investment, and ongoing maintenance.
In this article, I’ll explore a distinct yet related approach. It sidesteps KG embedding and empowers LLMs with basic analytical capabilities through tool calling (often referred to as agentic AI). I’ll showcase a tool enabling users to pose natural language questions directly to Wikidata.
For those eager to dive straight in, you can try the tool yourself at: https://wq42.toolforge.org
Textualization
In my experiment, I am going to use textualization, but without vector databases. And instead of RAG, tool calling LLMs will be used for anchoring the answers only on the information available in Wikidata.
Textualization—the conversion of a knowledge graph into a textual format consumable by ML techniques (like vector embedding or LLM prompting)—presents a significant hurdle with Wikidata. A straightforward API to retrieve all information linked to a specific QID (e.g., Q405 for the Moon) is conspicuously absent. In my previous two articles, I detailed how I developed a web API to fetch JSON-formatted data for a given item (qjson: Fetching all properties of a wikidata item in a single API call) and subsequently transformed this data into an LLM-friendly Markdown format (qrender: Render wikidata item in different formats).
The paper KG-LLM-Bench: A Scalable Benchmark for Evaluating LLM Reasoning on Textualized Knowledge Graphs (https://knowledge-nlp.github.io/naacl2025/papers/39.pdf) evaluates various data formats suitable for textualization. I came across this paper after developing qrender. My approach utilizes Markdown, incorporating links, images, and headings to represent the information associated with a given QID. A unique aspect of my method is the logical grouping of properties, ensuring similar attributes are clustered. For instance, when dealing with a person, details like various names (first, last, family, official, nickname), family connections, employment history, and awards are grouped cohesively. I’ve found this grouping crucial, as it significantly impacts the LLM’s output quality. Scattered or distracting information can heavily degrade LLM generation quality—a phenomenon recently dubbed ‘context rot.’
Tool Calling
So, how do we integrate an arbitrary LLM with the textualized form of a QID? First, the LLM must identify the appropriate QID(s) to answer a given question. Depending on the query, multiple QIDs might be necessary. For example, to answer “Which river is longer, the Nile or the Amazon?”, information for both “Nile” (Q3392) and “Amazon River” (Q3783) is required. Wikidata provides a web API to retrieve the QID for a given title in any supported language.
For example, to get the QID associated with Berlin, you can call: https://www.wikidata.org/w/api.php?action=wbsearchentities&search=Berlin&language=en&limit=10&format=json.
However, this API requires the entity’s title. For a given natural language question, how do we extract these titles? This is where LLMs shine. Without them, this would typically be a Named Entity Recognition (NER) task in NLP. For modern LLMs, it’s a relatively straightforward task.
We instruct the LLM to identify potential titles (one or more) and then use them to call the Wikidata API to fetch the corresponding QIDs. This requires an LLM configured for tool calling. LLMs, by themselves, don’t autonomously execute tool calls. Instead, when provided with a set of available tools—along with their descriptions, capabilities, and required parameters—an LLM can determine which tool to call and what parameters to pass.
So, I defined a tool as follows:
- Tool name:
get_wikidata_qid_for_title - Description: Retrieves potential Wikidata QIDs for a given title. For example, ‘Nile’ might return Q20631734 (male given name) and Q3392 (river), along with descriptions for disambiguation.
- Parameters:
{
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The title for which we need a QID. Examples: San Francisco, Kerala, James Webb Space Telescope"
}
},
"required": ["title"]
}
Once the LLM indicates this tool should be called and provides the necessary parameters, the orchestrating program executes the actual API call. The tool’s output (e.g., the JSON response from the Wikidata API) is then fed back to the LLM.
In our scenario, this would be the direct output from the wbsearchentities API call. A single title can match multiple QIDs. Therefore, we pass all matches along with their descriptions back to the LLM, allowing it to select the most relevant QID based on the question’s context. For instance, if the question concerns the Nile River, the API call https://www.wikidata.org/w/api.php?action=wbsearchentities&search=Nile&language=en&limit=10&format=json will return multiple matches:
- Q660835: Nile, American death metal band
- Q20631734: Nile, male given name
- Q3392: Nile, Major river in northeastern Africa
- …
The LLM is generally adept enough to discern that Q3392 is the relevant entity for a question about the river. Next, we need the textualized information for the selected QID (e.g., Q3392). We use the qrender library, outputting in Markdown format as previously discussed. This Markdown content is then passed back to the LLM. Crucially, each interaction with the LLM must include the history (original question, previous tool calls, and their responses), as these LLM calls are typically stateless.
To enable the LLM to use qrender, we must define it as another available tool:
- Tool name:
get_wikidata_information_for_qid - Description: Fetches comprehensive information from Wikidata for a given QID to help answer a question. The output is in Markdown format.
- Parameters:
{
"type": "object",
"properties": {
"qid": {
"type": "string",
"description": "The wikidata QID. Example: Q42"
}
},
"required": ["qid"]
}
With the qrender output, the LLM should have the necessary information to formulate an answer.
As mentioned, some questions necessitate multiple tool calls. For instance, comparing the lengths of the Nile and Amazon rivers requires fetching data for both QIDs, likely involving separate sequences of get_wikidata_qid_for_title and get_wikidata_information_for_qid calls for each river.
Code Execution
But can we trust an LLM to perform, say, a length comparison accurately? Analytical tasks, especially mathematical reasoning, are not inherently strong suits for many LLMs. The classic “How many ‘r’s are in ‘strawberry’?” puzzle often stumps them. Similarly, direct queries about which value is greater, or anything requiring precise calculation, can lead to unreliable LLM-generated answers. To address this weakness, we instruct the LLM not to perform calculations itself, but to delegate to a tool. What kind of tool? A simple calculator might not suffice for more complex logic.
I opted to equip the LLM with a more versatile tool: I instruct the LLM to generate code (in Lua, in this case) to perform these calculations. This generated code is then executed, and its result is returned to the LLM. I chose Lua because LLMs are generally proficient at writing small scripts, particularly in straightforward languages like it.
- Tool name:
run_lua_script - Description: Executes a given Lua script and returns its output. This should be used for mathematical, comparative, or analytical questions where precise computation is needed.
- Parameters:
{
"type": "object",
"properties": {
"script": {
"type": "string",
"description": "The Lua script to execute. Make sure to return the results. Printing the results has no effect."
}
},
"required": ["script"]
}
To illustrate, let’s revisit the “How many ‘r’s are in ‘strawberry’?” question. The LLM would be prompted to call run_lua_script with the following Lua code:
local subject = "strawberry"
local count = 0
for i = 1, #subject do
if string.sub(subject, i, i) == "r" then
count = count + 1
end
end
return count
The Lua script, when executed, returns 3. This result is then passed back to the LLM. The LLM can then confidently state: “There are 3 ‘r’s in ‘strawberry.’”
This, of course, requires a sandboxed Lua runtime environment for safe execution. Lua is an embeddable scripting language, and for this project, I integrated a Lua runtime within my Rust application.
The Prompt
Here’s the core prompt guiding WQ42:
You are WQ42, a Wikidata assistant. Answer user questions using ONLY provided tools.
* **Data-Driven:** Base answers strictly on Wikidata data from tool calls.
* **Concise & Clear:** Be informative but brief.
* **QID Attribution:** Include Wikidata QIDs as Markdown links: `[title](https://www.wikidata.org/wiki/QID)`.
* **Multimedia:** For links, audio, and video, present them in Markdown as follows: Use `` for images. `<audio controls><source src="audio_url"></audio>` for audio. `<video controls><source src="video_url"></video>` for video.
* **Wikipedia Articles:** When asked to generate article-like content, synthesize information in a Wikipedia style, using all available data and citing QIDs. Incorporate images, audio, and video where relevant and available.
* **Honest Limitations:** Respond "I don't know" if data is missing. Suggest Wikidata edits if information seems incomplete.
**Workflow:**
1. Get user query.
2. Use `get_wikidata_qid_for_title` to find QID (if needed).
* **If the FIRST `get_wikidata_qid_for_title` call fails (returns no results), try `get_wikidata_qid_for_title` again using a more general term from the query.** For example, if the query is "What is the national anthem of India?" and "National anthem of India" fails, try "India".
3. Use `get_wikidata_information_for_qid` to get data.
4. For any mathematical or analytical questions, generate Lua code and use `run_lua_script` to execute it. Use the output from code execution to answer the question. For example, when asked "How many 'r's are there in 'raspberry'?" or "Which is longest?" etc., generate Lua code to calculate and return the answer.
5. Answer concisely, with QIDs and media.
Avoid making assumptions. Prioritize accuracy. If Wikidata's data appears incomplete or outdated, politely suggest the user consider contributing to Wikidata.
For this experiment, I utilized the “google/gemini-2.5-flash-preview” model via OpenRouter.
Examples and Screenshots
You can experience the tool firsthand at https://wq42.toolforge.org. Below are a few screenshots demonstrating its capabilities.
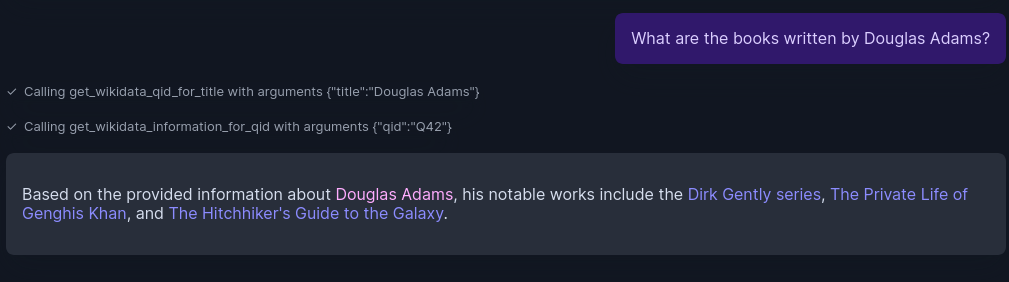
Question: What are the books written by Douglas Adams?
This is a straightforward query. The process involves finding the QID for Douglas Adams, retrieving the textualized information via qrender, and presenting the relevant data.
Qn: “Among the following countries, which country gained independence first: Keya, Singapore, or India?”
This is a multi-hop question, requiring information from multiple entities. WQ42 is designed to fetch information for all three countries. I intentionally misspelled “Kenya” as “Keya” to test the LLM’s Named Entity Recognition robustness. The answer provided is correct. However, I anticipated the comparison logic would be offloaded to Lua code execution rather than being handled directly by the LLM’s reasoning. There’s also a minor formatting issue in the example output: the links aren’t rendered correctly.
Qn: What is the national anthem of Japan?
This is a simple question. Note the presentation of answer though. A user can play the national anthem right away.
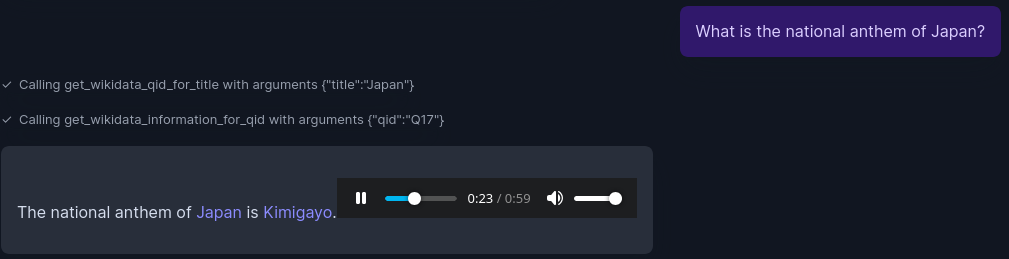
Qn: Write an essay about Kanchenjunga.
This is a test to see how LLM can paraphrase all the information available. One of the challenge for LLMs for this kind of task is avoid deviate from supplied information to LLM’s own information. As I had instructed in prompt, links are provided wherever possible. Image is also provided.
Qn: What does a Lion’s sound like?
This is a simple question. Instead of providing the link as text, an audio player is given as instructed in prompt.
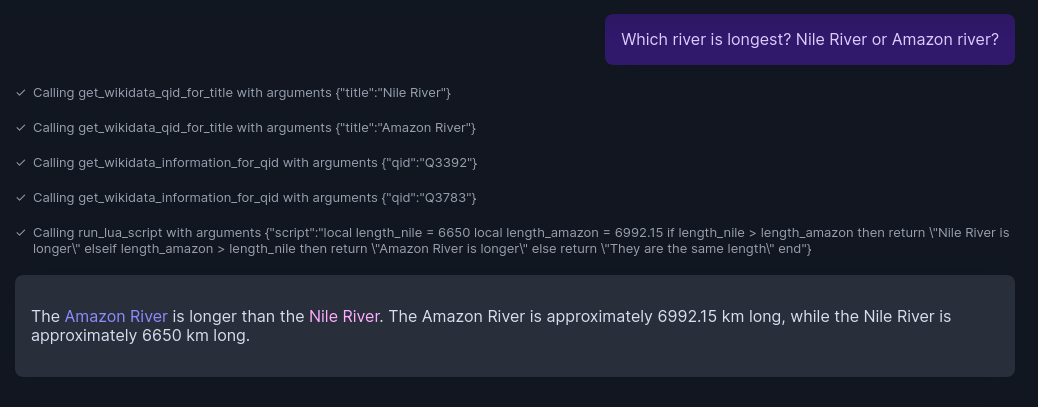
 Qn: Which river is the longest? Nile river or Amazon river?
Qn: Which river is the longest? Nile river or Amazon river?
This is an analytical, multi-hop question. After fetching required information, Lua code is written and executed to find which is longer.
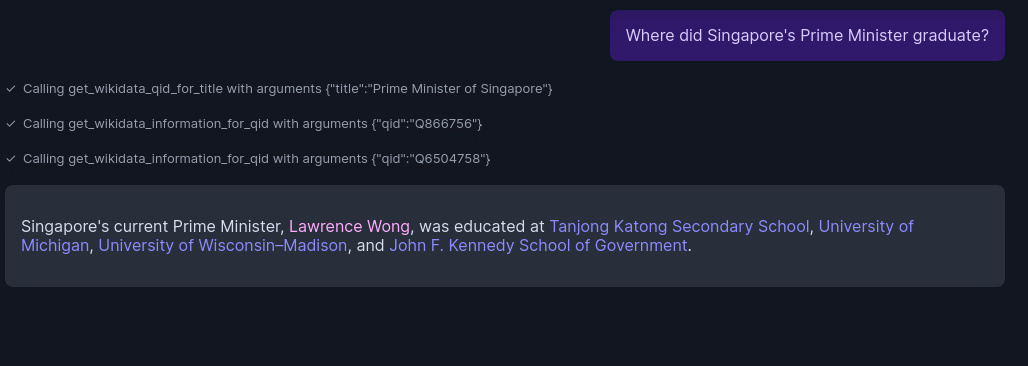
Qn: Where did Singapore’s Prime minister graduate?
This is a multi-hop question. First, wq42 fetches information from Prime minister of Singapore item. From there, LLM picks the current prime minister’s QID. Fetches information about it and answers the question. Using “Prime minister of Singapore” as title for searching is LLM’s skill.
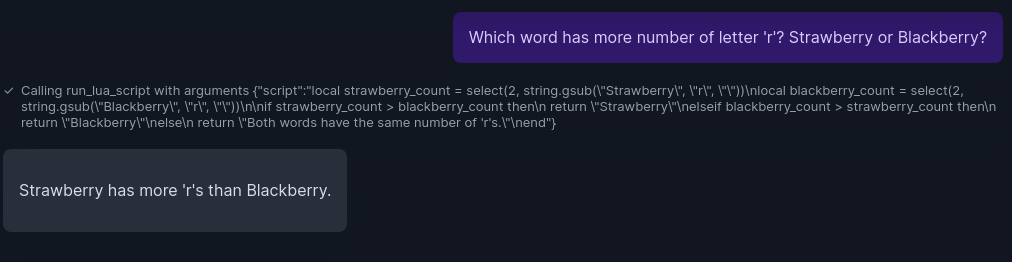
 Qn: Which word has more number of ‘r’? strawberry or blackberry?
Qn: Which word has more number of ‘r’? strawberry or blackberry?
This has nothing to with Wikidata, but given as an example for Lua code execution.
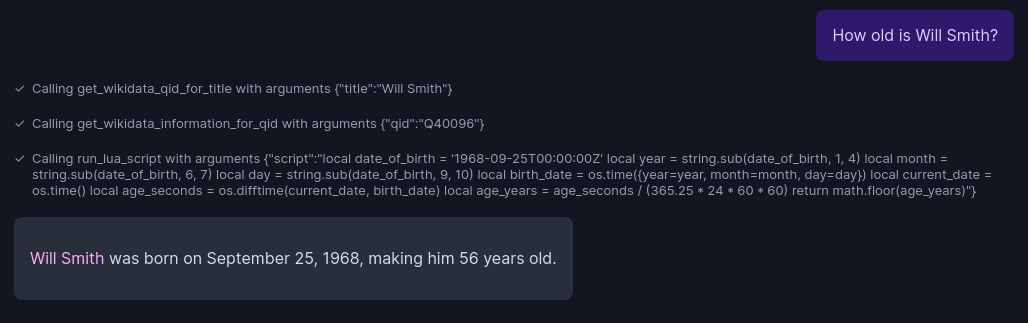
Qn: How old is Will Smith.
The Wikidata item about Will Smith will give date of birth. From it, we get Year too. But to calculate age, a small math operation is needed based on current date. LLM writes Lua code and executes as expected.
Discussion
One of the defining characteristics of WQ42 is its deliberate avoidance of vector databases. This design choice also means there’s no inherent knowledge cut-off date; the system sources its information dynamically and directly from Wikidata (barring any potential caching by the underlying qjson library). This ensures responses are based on the most current data available in the knowledge graph.
The efficacy of tool calling can indeed vary depending on the specific LLM employed. While less sophisticated models might occasionally hesitate or fail to invoke a tool when one is clearly required, this issue is notably less prevalent with more advanced models, such as Google’s Gemini series. The reliability of the LLM’s decision-making in tool invocation is critical for consistent performance.
There is a set of problems that WQ42 cannot address right now. One set of such questions are the ones that require data beyond Wikidata(obviously!). Wikidata only has facts and there is wast amount of knowledge outside the facts. “How do snakes move?”, “How do I tie a Windsor Knot?” are some examples.
Multi-hop and analytical questions are not fully solved with the system. Even though I shared some examples of simple math, analytical and multi hop questions.
For example, “Which Turing Award winners were born in Latin America?” WQ42 Answers: “I’m sorry, I cannot answer which Turing Award winners were born in Latin America. While I can find information about the Turing Award and its laureates, I don’t have the ability to filter laureates by their birthplace”
This response, while commendably honest and even providing a helpful link to the Turing Award’s Wikidata page, ultimately doesn’t satisfy the user’s specific information need. Answering this require designing more tools carefully and figuring out smart ways to procure the raw information to use with that tools. The paper I linked in the beginning of this article has many examples and very elaborate classification of these questions. If anybody interested in solving these limitations, please contact me.
There are also few questions that I don’t have answer yet:
- Instead of Lua sandbox, imagine connecting with wikifunctions - an encyclopedia of functions in making. What would be the pros and cons?
- LLMs are good in a few dozen languages as of today? What can we do to extend this approach for more languages?
- The wbsearchentities API searches in Wikidata item titles(labels). If there is a wikidata API that allows fuzzy search over the item information, can we expand the category of questions that can be answered?
- How does this approach compares with SPARQL query generation approaches?
I came across your recent paper titled “Conversational Lexicography: Querying Lexicographic Data on Knowledge Graphs with SPARQL through Natural Language”. The authors attempted to generate SPARQL queries for natural language questions about Wikidata lexemes. I am tempted to try and find if the approach I outlines here work for that use case.
Finally, WQ42 is presented here as an exploratory project—an ongoing dive into a fascinating and complex problem—rather than a polished, production-ready application. Thanks for reading! 😊
Source code
Source code: https://gitlab.wikimedia.org/toolforge-repos/wq42 The tool is written in Rust programming language.
Disclaimer
I work at the Wikimedia Foundation. However, this project, its exploration, and the opinions expressed are entirely my own and do not reflect my employer’s views. This is not an official Wikimedia Foundation project.