Many months back, I started an experiment to see if Malayalam handwriting recognition can be done in a non-machine learning based approach. This blog post explains the approach, the work done so far and results.
Handwriting recognition can be done while the user is writing(called online handwriting recognition) and recognizing a sample somebody wrote in the past(offline recognition). Online and offline recognition problems are different problems. This is because, in online recognition, it is possible to capture additional details such as pen up, pen down, pen movement directions and rotations. These details provide an extra advantage on recognition. In offline recognition, we only have a sample written by somebody in the past. It is also important to note that optical character recognition(OCR) for printed content on a paper has differences with handwriting recognition. Printed content often have regularities(single font, uniformly aligned content etc.)
My experiment was about online handwriting recognition.
Approach
In general, our problem is pattern matching of curves. The curves get complicated depending on the script. The curves are also very irregular because this is written by a user on a touch interface, mostly mobiles, using fingers(rarely, a stylus). So, we need a set of base representation of these curves and then compare the curves from user input and see if how close they are with the reference images.
The curves and strokes
The curves created in a two dimensional space can be represented by x,y coordinates. We need the coordinates at start, end positions of a drawing. Start is “pen down” point and end is “pen up” point for a handwriting. We also need to get coordinates for all relevant intermediate points in the curve. These relevant points are inflection points. So when we have [(0,10), (20, 30)], we mean a straight line from (0,10) to (20, 30). Note that we are assuming straight lines between each points. This is approximation of any possible path between those two points.
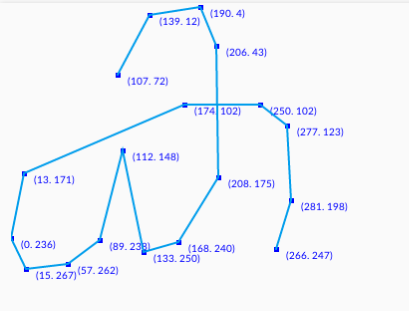
This is just one way of writing ക. It is possible that there are more than one style of writing a letter. We can use that also as base image. ക is usually written with a single stroke. Meaning, you take the pen up only after writing the full letter. But consider the letter +- it has two strokes. You need to take the pen up after a stroke. We also need to make sure that the direction of pen movement is taken into consideration. So the array of points should follow the same order of pen movement.
Considering all these, we can have a representation of reference image of ക as :
We can represent it in a json format.
"ക": {
"samples": [
{
"strokes": [
[
{"x": 107, "y": 72 },
{"x": 139, "y": 12 },
{"x": 190, "y": 4 },
{"x": 206, "y": 43 },
{"x": 208, "y": 175 },
{"x": 168, "y": 240 },
{"x": 133, "y": 250 },
{"x": 112, "y": 148 },
{"x": 89, "y": 238 },
{"x": 57, "y": 262 },
{"x": 15, "y": 267 },
{"x": 0, "y": 236 },
{"x": 13, "y": 171 },
{"x": 174, "y": 102 },
{"x": 250, "y": 102 },
{"x": 277, "y": 123 },
{"x": 281, "y": 198 },
{"x": 266, "y": 247 }
]
]
}
]
},
How to prepare the curve data
The above data should be prepared for every letter in the script. That is very tedious process. We need some tool to get this representation when we draw it. So I wrote a javascript application with an HTML5 canvas where you draw ,using mouse or finger and get this simplified representation of the curve.
Curve simplification is an interesting problem, but fortunately I did not had to implement it myself. There is an excellend javascript library that does exactly this, named simplifyjs. I just used it. It also allows setting the smoothness factor, depending on that we get more points to represent a curve or less points.
Compare the writing
So, once we have the reference data prepared for a letter, we should compare it against a representation of user drawn letter. This is the core part of handwriting recognition. As far as the user interface is concerned, you can imagine that there is a canvas where a user can draw a letter using finger or mouse or stylus. We get a representation of that drawing in the same data structure we used for reference image.
Comparing to irregular curves for a match is a difficult problem. One curve may be bigger than other. One may be smoother than other. We need accommodate all kind of distortions. The drawing may be tilted too. There is a technique to compare two shapes considering all these challenges - Procrustes Analysis.
Procrustes Analysis
In statistics, Procrustes analysis is a form of statistical shape analysis used to analyse the distribution of a set of shape(See Procrustes Analysis, Wikipedia). To compare the shapes of two or more objects, the objects must be first optimally “superimposed”. Procrustes superimposition (PS) is performed by optimally translating, rotating and uniformly scaling the objects.

Procrustes superimposition. The figure shows the three transformation steps of an ordinary Procrustes fit for two configurations of landmarks. (a) Scaling of both configurations to the same size; (b) Transposition to the same position of the center of gravity; (c) Rotation to the orientation that provides the minimum sum of squared distances between corresponding landmarks.
(Image credit: Wikimedia commons Author: Christian Peter Klingenberg, Uploaded by user:Was a bee )
For comparing a letter drawn by a user with the reference image, same approach was used. They are compared by rotating and scaling. the rotation is limited to 45 degree. Otherwise z and s may match!. Rotation and scaling is done in steps and at each step a score of match is calculated. If it cross a predefined threshold, we declare it as a match.
For Procruster based matching, I used curvematcher library
Implementation
The software implementation of this system has the following parts
- The reference image database in json format
- The matching logic
- The user interface of the system
- The training UI or UI to easily create the reference data.
Source code is availabe at gitlab and ou can try the system here: https://smc.gitlab.io/handwriting
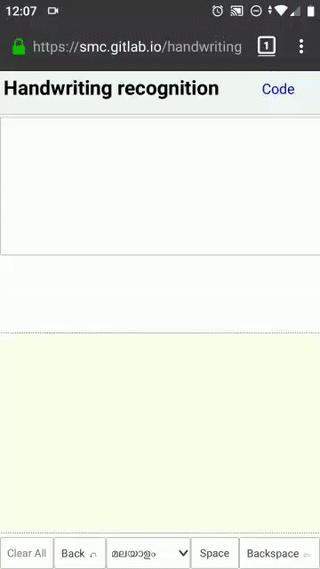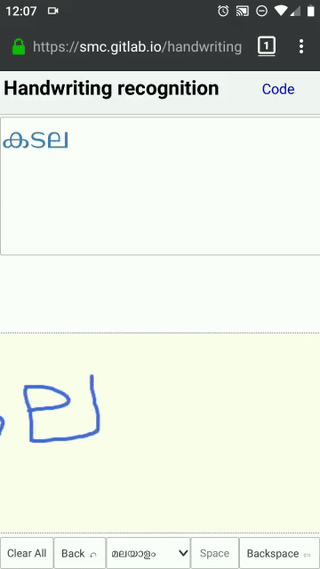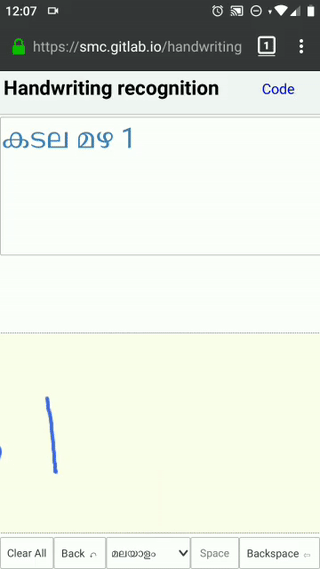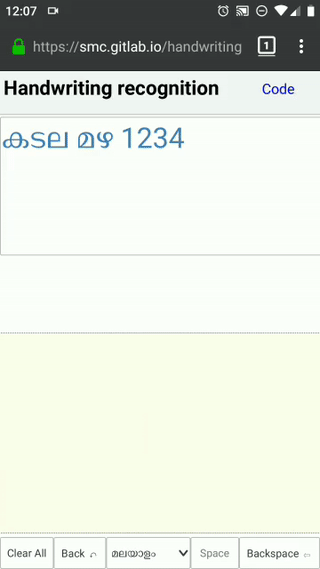
{kind=link}
As you can observe from the above video, the letter ‘4’ is a multistroke letter. This is supported by checking if the pen down of second stroke is within the drawing box of previous stroke. You can also see distortions, writing angle, spacing - all taken care of.
Training
To prepare the reference data, a web application is being developed. It is similar to the handwriting recognition, but here a developer will draw a letter and tell which character it is. This data is then exported to the json file.
It is available at https://smc.gitlab.io/handwriting/training
This application is still missing many features.
What is next
- Expand the reference data to cover most of common malayalam script.
- Expand further with style alternatives for each letter.
- Reduce the UI glitches
- Finish the training UI
- Convert it as a real input method that works with Operating systems, so that you can type directly to applications.
- An experimental support for Tamil is added. Enhance that with the help of Tamil speaking friends.
- More languages.
- Post-recognition corrections of words using spellcheck, predictive entry mechanisms likes Markov chain can improve the accuracy significantly.
- While writing letters like “കോ”, we write േ sign first, while the actual data is ക + ോ. So we need a visual to unicode reordering logic.
I am not getting enough time to spend on this project these days. If anybody interested in helping, please contact me.
Anish was contributing to this project recently. He presented this project in IndiaOS 2020(Video)
Advantages
This approach is able to handle a large variety of irregular curves in handwriting without learning each and every such possibilities. Machine learning approach require large collection of handwriting samples. Here even with one sample, we can recognize so many variations. Additional provision of supporting style variants are also provided.
There is nothing script specific in this approach. So, using this for another language like Tamil is very easy. Note that if the script has connective writing like English running letter, our approach has a serious issue - we rely on ‘pen ups’ for identifying ligatures.
Drawbacks
While the script characteristics of Malayalam or other languages discussed here can provide some advantages in the approach, it should not be forgotten that a normal user also usually writes English content. The English content can be in running letter style too. So quickly the problem becomes multi-script handwriting recognition. Unlike the keyboards which provide explicit script selection, handwriting recognition systems are better if it works without such language switch.
The system is written in javascript, but it may be difficult to get intergrated with Operating system to act as native input method. Jishnu tried to port this as react native application(Code)