A demo of cross language approximate search in Indic text:
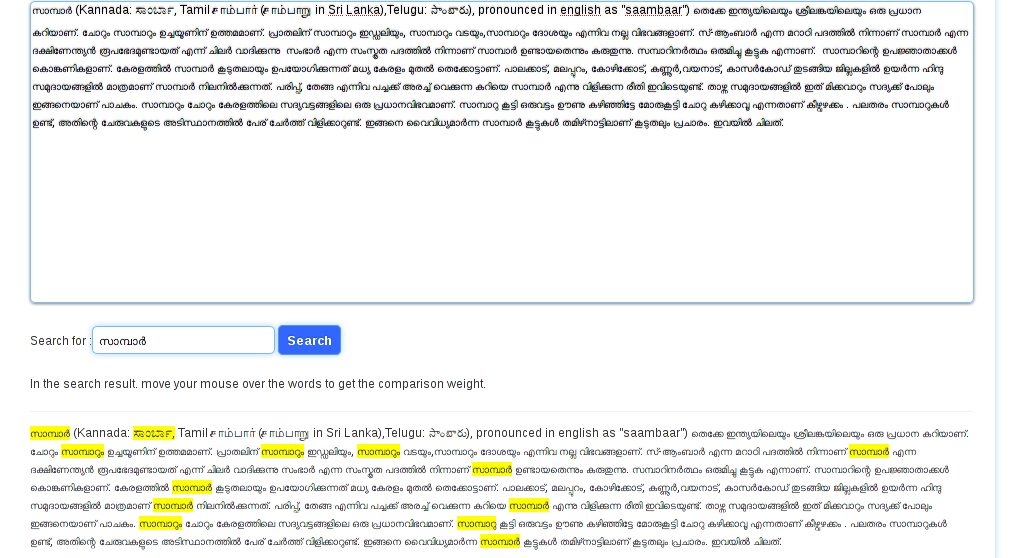
The Malayalam word സാമ്പാര് is compared against a paragraph from http://ml.wikipedia.org/wiki/Sambar.
In the bottom half, words marked in yellow color are search results.
You can see that a Kannada word ಸಾಂಬಾರ್ is matched for Malayalam word. And that is why this is called cross-language.
The inflections of the words സാമ്പാര് – സാമ്പാറും, സാമ്പാറു etc are also found as results.
This is the kind of search we need in Indic languages, not just the letter by letter comparison we do for English.
Another example showing all inflection forms of the noun പാലക്കാട്, and the same word written in Tamil, Telugu, Hindi. The search shows the results in those languages too. – 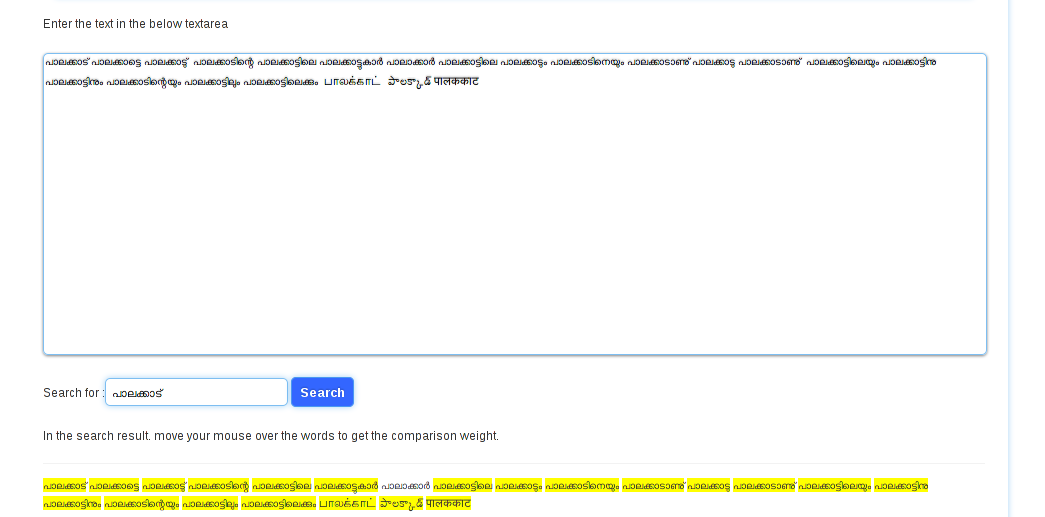
You can try it here: http://silpa.org.in/ApproxSearch
This is a Fuzzy string search application. This application illustrates the combined use of Edit distance and Indic Soundex algorithm.
By mixing both written like(edit distance) and sounds like(soundex), we achieve an efficient aproximate string searching. This application is capable of cross language string search too. That means, you can search Hindi words in Malayalam text. If there is any Malayalam word, which is approximate transliteration of hindi word, or sounds alike the Hindi words, it will be returned as an approximate match. The “written like” algorithm used here is a bigram average algorithm. The ratio of common bigrams in two strings and average number of bigrams will give a factor which is greater than zero and less than 1. Similarly the soundex algorithm also gives a weight. By selecting words which has comparison weight more than the threshold weight(which 0.6), we get the search results.