ഓരോ ഭാഷയിലും അതിലെ ലിപികളെ ഒരു പ്രത്യേക ക്രമത്തിൽ എഴുതുന്ന ഒരു കീഴ്വഴക്കം ഉണ്ടു്. ഇംഗ്ലീഷിൽ A,B,C,D എന്ന ക്രമമാണെങ്കിൽ മലയാളത്തിലത് അ, ആ, ഇ, ഈ എന്നിങ്ങനെ തുടങ്ങുന്ന ക്രമമാണുള്ളതു്. ഇങ്ങനെ ഒരു കീഴ്വഴക്കം കൊണ്ടു് പല പ്രയോജനങ്ങളുമുണ്ടു്. നമുക്കെല്ലാം പരിചയമുള്ള നിഘണ്ടുവിൽ നോക്കലും, കുറേ പേരുടെ പട്ടികയിൽ നിന്നെളുപ്പത്തിൽ ഒന്ന് കണ്ടുപിടിക്കലും ഒക്കെ ഉദാഹരണം. കീഴ്വഴക്കം എന്നതിൽ കവിഞ്ഞ് എന്തെങ്കിലും കൃത്യമായ ശാസ്ത്രീയതയൊന്നും ഈ ക്രമീകരണത്തിൽ കാണണമെന്നില്ല.
അയിൽ തുടങ്ങുന്ന ഈ ക്രമത്തിനു് മലയാളത്തിൽ അകാരാദിക്രമമെന്നും പറയുന്നു. അക്ഷരമാല പൊതുവിൽ അകാരാദിക്രമത്തിലാണു് എഴുതുന്നതും പഠിക്കുന്നതും. സാമാന്യേന ഈ ക്രമം മലയാളികളെല്ലാം അറിഞ്ഞിരിക്കുന്നതാണ്. അക്ഷരങ്ങളൊറ്റയ്ക്കുള്ള ക്രമം അല്ലാതെ കുറേ വാക്കുകൾ തന്നാൽ അതെങ്ങനെ ക്രമീകരിക്കും എന്ന പ്രശ്നം കുറേകൂടി സങ്കീർണ്ണമാണ്. അവിടെ അക്ഷരങ്ങളുടെ കൂടെ സ്വരചിഹ്നങ്ങൾ ചേരും, കൂട്ടക്ഷരങ്ങൾ വരും, ചില്ലുകൾ വരും. ഭാഷയുടെ തന്നെ ചില പ്രത്യേകതകളായ റ്റ, ന്റ എന്നിവ വരും, എഴുത്തിലെ വൈവിധ്യങ്ങളായ നൻമ, നന്മ പോലുള്ള വാക്കുകൾ വരും. അവിടെയാണ് അക്ഷരമാലാക്രമം എന്ന ലാളിത്യത്തിൽ നിന്നും സങ്കീർണ്ണവും പലപ്പോഴും കൃത്യതയില്ലാത്തതുമായ ക്രമീകരണ നിയമങ്ങളിലേക്ക് നാം എത്തുന്നതു്.
അച്ചടി, എഴുത്തു് തുടങ്ങിയ മാർഗങ്ങളിൽ നിന്നും ഡിജിറ്റൽ ഡാറ്റ എന്ന രൂപത്തിലേക്ക് ഭാഷ എത്തുമ്പോൾ ഈ ക്രമത്തിനു് ഒരുപാടു പ്രാധാന്യം കൈവരുന്നുണ്ടു്. വിവരങ്ങളുടെ കൂട്ടങ്ങളെ പ്രോഗ്രാമുകൾക്കു് അടുക്കിവെയ്ക്കേണ്ടിവരുന്നതു് ഡിജിറ്റൽ ലോകത്തിലെ ഒരു സാധാരണ കാര്യമാണ്. മലയാളം വാക്കുകളെ സംബന്ധിച്ച അകാരാദിക്രമീകരണ നിയമങ്ങൾ അപ്പോൾ കൈകാര്യം ചെയ്യുന്നതു് പ്രോഗ്രാമുകളാണു്. ഈ ലേഖനത്തിൽ നമ്മൾ ഇതേപറ്റിയാണ് ചർച്ച ചെയ്യുന്നതു്. അകാരാദിക്രമീകരണത്തെ സംബന്ധിച്ച മാനകങ്ങളെന്താണ്, ക്രമീകരണ രീതികളുടെ യുക്തി എന്താണ്, മാനകങ്ങളും നിഘണ്ടുക്കളും ഒക്കെ എങ്ങനെയൊക്കെ വ്യത്യാസപ്പെട്ടിരിക്കുന്നു എന്നെല്ലാം ഉദാഹരണങ്ങളുടെ സഹായത്തോടെ നമുക്ക് വിശദമായി പരിശോധിക്കാം
നിഘണ്ടുക്കളിലെ അകാരാദിക്രമം
മലയാളത്തിലെ നിഘണ്ടുക്കൾ പരിശോധിച്ചാൽ അവയുടെ ആമുഖത്തിൽ തന്നെ ഉപയോഗിച്ചിരിക്കുന്ന ക്രമത്തിനെപ്പറ്റി ചെറിയ വിവരണം കാണാനാകും. സ്വരാക്ഷരങ്ങൾ, അഞ്ച് വ്യഞ്ജനങ്ങൾ എന്നീ ക്രമം എല്ലാവരും പാലിക്കുന്നുണ്ടു്. എങ്കിലും ഗുണ്ടർട്ടിന്റെ നിഘണ്ടുവിൽ യ, ര, റ എന്ന ക്രമമാണുള്ളതു്. അതേസമയം ശബ്ദതാരാവലി റ ഏറ്റവും അവസാനം കൊടുക്കുന്നു. ചില്ലുകൾ, കൂട്ടക്ഷരങ്ങൾ എന്നിവയുടെ കാര്യത്തിലും വലിയ വ്യത്യാസങ്ങൾ കാണുന്നുണ്ടു്. അതുകൊണ്ടു് ഏതെങ്കിലും ഒരു നിഘണ്ടു ശരിയാണെന്നോ മറ്റൊന്ന് തെറ്റാണെന്നു പറയാനോ കഴിയില്ല. ഓരോ നിഘണ്ടുവും സ്വീകരിച്ച ക്രമങ്ങളും അതിനു പിന്നിലെ യുക്തിയോ വിശദീകരണമോ മനസ്സിലാക്കാൻ ശ്രമിക്കുക എന്നതിനുമാത്രമേ പ്രസക്തിയുള്ളൂ.
ഈ പ്രശ്നം നിഘണ്ടു പ്രസാധകർ തന്നെ നന്നായി തിരിച്ചറിഞ്ഞിട്ടുണ്ട്. ശബ്ദതാരാവലിയുടെ നാലാംപതിപ്പിന് പ്രസാധകൻ ശ്രീ പി ദാമോദരൻനായർ എഴുതിയ ആമുഖത്തിലെ താഴെക്കൊടുത്തിരിക്കുന്ന ഭാഗം നോക്കൂ.

നിഘണ്ടുക്കൾക്കു പുറമേ കേരള സർക്കാറിന്റെ സർവ്വവിജ്ഞാനകോശത്തിലും ഒരു പ്രത്യേക അകാരാദിക്രമം പിന്തുടരുന്നുണ്ടു്.
ഇവയെല്ലാം ഓരോ ലിപിഗണങ്ങളുടെ അകാരാദിക്രമം വിശദീകരിക്കുമ്പോൾ ഓരോന്നായി പരിചയപ്പെടാം.
സ്റ്റാൻഡേഡുകൾ, ലൈബ്രറികൾ
അകാരാദിക്രമത്തിന്റെ അടിസ്ഥാന തത്വം രണ്ടു വാക്കുകൾ അല്ലെങ്കിൽ ഒന്നോ അധിലധികമോ അക്ഷരങ്ങളുടെ ഒരു ശ്രേണി കിട്ടിയാൽ ഏത് ആദ്യം ക്രമീകരിക്കണം എന്ന String comparison അൽഗോരിതമാണ്. ഈ അൽഗോരിതം എല്ലാ വാക്കുകൾക്കും അപ്ലൈ ചെയുമ്പോൾ ആ വാക്കുകളെല്ലാം ക്രമത്തിലാവും. ഈ അൽഗോരിതത്തെ സംബന്ധിക്കുന്ന പ്രധാന മാനകം ISO 14651 ആണ്.
ISO/IEC 14651:2011, Information technology — International string ordering and comparison — Method for comparing character strings and description of the common template tailorable ordering, is an ISO Standard specifying an algorithm that can be used when comparing two strings.
ഈ മാനകമനുസരിച്ചു് ഒന്നിലധികം കൊളേഷൻ സ്പെസിഫിക്കേഷനുകളും ഡാറ്റ സെറ്റുകളും ഉണ്ടു്. അതിലെ ഏറ്റവും പ്രധാനം യുണിക്കോഡ് കൊളേഷൻ അൽഗോരിതം (UCA) ആണ്. യുണിക്കോഡ് എന്ന വലിയ സ്റ്റാൻഡേഡിനകത്ത് ടെക്നിക്കൽ റിപ്പോർട്ട് 10 ആയി വരുന്ന ഈ സ്പെസിഫിക്കേഷൻ , അതിന്റെ കൂടെത്തന്നെ യുണിക്കോഡ് എൻകോഡ് ചെയ്തിട്ടുള്ള എല്ലാ കാരക്ടറുകളുടെയും കൊളേഷൻ ക്രമം പ്രതിപാദിക്കുന്ന Default Unicode Collation Element Table (DUCET) – ഇതാണ് ഇന്നത്തെ കാലത്തെ ഏതു ഭാഷയിലെയും അക്ഷരങ്ങളുടെ ക്രമം നിർവചിക്കുന്ന അടിസ്ഥാന പ്രമാണം.
ഈ സ്പെസിഫിക്കേഷൻ പക്ഷേ അതിന്റെ തന്നെ നിർവചനമനുസരിച്ചു് പ്രായോഗികമായി ഉപയോഗിക്കുന്നതിനു് അപൂർണ്ണമാണ്. ഭാഷാ നിയമങ്ങൾ ഇതിന്റെ മുകളിൽ ചേർത്ത് ടെയിലർ ചെയ്യണമെന്ന് അതുതന്നെ അനുശാസിക്കുന്നു.
Tailoring consists of any well-defined change in the Collation Element Table and/or any well-defined change in the behavior of the algorithm. Typically, a tailoring is expressed by means of a formal syntax which allows detailed manipulation of values in a Collation Element Table, with or without an additional collection of parametric settings which modify specific aspects of the behavior of the algorithm. A tailoring can be used to provide linguistically-accurate collation, if desired.
ഇങ്ങനെ ഭാഷയ്ക്കനുരൂപമാക്കിയ ക്രമീകരണ നിയമങ്ങൾ Unicode Common Locale Data Repository [CLDR] എന്ന റിപ്പോസിറ്ററിയിലാണുള്ളതു്. യുണിക്കോഡ് അധിഷ്ഠിതമായ അൽഗോരിതങ്ങൾക്കും മറ്റുമുള്ള ഡാറ്റ സന്നദ്ധപ്രവർത്തകരാണ് ഇവിടെ സംഭരിക്കുന്നതു്. ആർക്കും ഇതിലേക്ക് ഡാറ്റകൾ ചേർക്കുകയും തിരുത്തുകയും ചെയ്യാം. CLDR ൽ യുണിക്കോഡ് കൊളേഷൻ അൽഗോരിതത്തിന്റെ മുകളിലുള്ള, ലിംഗ്വിസ്റ്റിക് കറക്ഷനുകൾ ചെയ്യാനുള്ള തരത്തിൽ CLDR Collation അൽഗോരിതവും ഉണ്ടു്.
പക്ഷേ ഇതൊക്കെയും അൽഗോരിതവും ഡാറ്റയും മാത്രമാണല്ലോ. അതിന്റെ പുറത്തു് ആരെങ്കിലും ശരിക്കും വാക്കുകൾ ക്രമീകരിക്കാനുള്ള പ്രോഗ്രാം എഴുതണമല്ലോ. അങ്ങനെ എഴുതിയ സോഫ്റ്റ്വെയർ ലൈബ്രറികളിലൊന്നാണ് ICU Project – International Components for Unicode. ഈ ലൈബ്രറി ഉപയോഗിച്ച് ഒരു അപ്പ്ലിക്കേഷന് ഏതു ഭാഷയ്ക്കുമുള്ള ക്രമീകരണം സാധ്യമാക്കാം.
GNU C library localedata
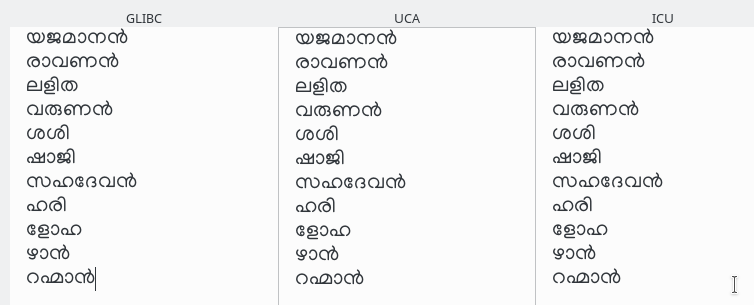
നേരത്തെ പറഞ്ഞ ISO 14561 അനുസരിച്ചുള്ള വേറെയും അൽഗോരിതവും അതനുസരിച്ച് ഉള്ള അപ്ലിക്കേഷൻ ലൈബ്രറികളുമുണ്ടു്. അതിൽ പ്രധാനം GNU സി ലൈബ്രറിയാണ്. സ്വതന്ത്ര സോഫ്റ്റ്വെയർ പ്രസ്ഥാനത്തിന്റെ അതിപ്രധാനവും വളരെ പഴക്കമുള്ളതുമായ സ്വതന്ത്ര സി കമ്പൈലറിന്റെ ഭാഗമാണ് ഈ ലൈബ്രറി. അതിൽ string comparison സംവിധാനമുണ്ടാവുമെന്നു പറയാതെത്തന്നെ അറിയാമല്ലോ. ഈ ലൈബ്രറി പക്ഷേ യുണിക്കോഡ് കൊളേഷൻ ഡാറ്റ ഉപയോഗിക്കുന്നില്ല. പകരം സ്വതന്ത്ര സോഫ്റ്റ്വെയർ ഡെവലപ്പർമാർ ചേർത്ത അക്ഷരക്രമീകരണ നിയമങ്ങളാണ് ഉപയോഗിക്കുന്നതു്. സ്വതന്ത്ര സോഫ്റ്റ്വെയർ ലോകത്തിലെ ഭൂരിപക്ഷം അപ്ലിക്കേഷനുകളും ഒരുതരത്തിലല്ലെങ്കിൽ മറ്റൊരുതരത്തിൽ ഈ GNU C library യെ ആധാരമാക്കിയായതുകൊണ്ടു് പ്രായോഗികമായി ഇതിൽ എന്തു് അകാരാദിക്രമമാണോ ഉള്ളതു്, അതാണ് കിട്ടുക. ഉദാഹരണത്തിനു ലിനക്സിലെ sort കമാന്റ് ഒക്കെ തരുന്ന മലയാളത്തിന്റെ സോർട്ടിങ്ങ് ഇതുപ്രകാരമാണ്. അതുപോലെ പൈത്തണിലെ Locale packageന്റെ സോർട്ടിങ്ങ്.
GNU C library യുടെ ഉള്ളിലുള്ള മലയാളത്തിന്റെ അകാരാദിക്രമം എഴുതിയിരിക്കുന്നതു് ഞാനാണ്.
അപ്പോൾ നമുക്ക് മൂന്നിടത്തു് നിയമങ്ങളുണ്ടു്:
- Unicode Default Collation Element Table ൽ ഉള്ള മലയാള അക്ഷരങ്ങളുടെ ക്രമം Unicode Collation Algorithm(UCA) അനുസരിച്ചിട്ടുള്ളതു്
- CLDR ലെ ഡാറ്റ ഉപയോഗിച്ച് ICU ഇംപ്ലിമെന്റ് ചെയ്ത മലയാളം കൊളേഷൻ
- GNU C library യിലെ മലയാളം കൊളേഷൻ.
ഇനി ഈ ലേഖനത്തിൽ മലയാളത്തിലെ അക്ഷരങ്ങളുടെ അകാരാദിക്രമീകരണം ചർച്ച ചെയ്യുമ്പോൾ ഈ മൂന്ന് നിയമങ്ങൾ എങ്ങനെ വ്യത്യാസപ്പെട്ടിരിക്കുന്നു എന്നു വിശദമാക്കുന്നതാണ്.
സ്റ്റാൻഡേഡുകൾ എന്ന ബഹുവചനത്തിന്റെ അനൌചിത്യം ഈ ഭാഗത്തിന്റെ തലക്കെട്ടിനുണ്ടെങ്കിലും അതെങ്ങനെ വന്നു എന്നു മനസ്സിലായിക്കാണുമെന്നു കരുതുന്നു. അല്ലെങ്കിലും സ്റ്റാൻഡേഡ് എപ്പോഴും ബഹുവചനം തന്നെയാണല്ലോ!
പൊതുവായ നിയമങ്ങൾ
അക്ഷരമാലയിലെ പൊതുവായ ക്രമം താഴെക്കൊടുക്കുന്നു:
അ ആ ഇ ഈ ഉ ഊ ഋ എ ഏ ഐ ഒ ഓ ഔ അം അഃ ക ഖ ഗ ഘ ങ ച ഛ ജ ഝ ഞ ട ഠ ഡ ഢ ണ ത ഥ ദ ഥ ന പ ഫ ബ ഭ മ യ ര ല വ ശ ഷ സ ഹ ള ഴ റ

ഇതിൽ, റ അവസാനം കൊടുത്തിരിക്കുന്നതു് എല്ലാ നിഘണ്ടുക്കളും ഒരു പോലെ പാലിക്കുന്നില്ല. ഉദാഹരണത്തിന് 1871 ലെ ഗുണ്ടർട്ടിന്റെ നിഘണ്ടുവിൽ ര കഴിഞ്ഞ് റ കൊടുത്തിരിക്കുന്നു. കുറച്ചു കൂടി കൃത്യമായിപ്പറഞ്ഞാൽ യ, ര, ർ, ൎ , റ, റ്റ, ല എന്ന ക്രമമാണ് ഗുണ്ടർട്ട് ഉപയോഗിക്കുന്നതു്.
ഇതേക്രമം സർവവിജ്ഞാനകോശവും പിന്തുടരുന്നു. അർക്കൻ കഴിഞ്ഞ് ‘ല, ശ, സ’കളിൽ അനേകം പദങ്ങൾ വന്നശേഷം അറ കൊടുക്കുന്നതിന് ഉപപത്തിയില്ല – എന്ന് വിശദീകരണം കൊടുത്തിരിക്കുന്നു.
മലയാളത്തിന്റെ യുണിക്കോഡ് ബ്ലോക്ക് ര, റ എന്ന രീതിയിലാണ് കോഡ് പോയിന്റുകൾ കൊടുത്തിട്ടുള്ളത്. രയുടെ കോഡ് പോയിന്റ് 0D30, റയുടെത് 0D31, അതുകഴിഞ്ഞ ലയുടെത് 0D32 എന്ന രീതിയിൽ. ലിംഗ്വിസ്റ്റിക് നിയമങ്ങളോ യുണിക്കോഡ് കൊളേഷൻ നിയമങ്ങളോ പാലിക്കാത്ത ഒരു സിസ്റ്റത്തിന്റെ ഫോൾബാക്ക് ക്രമം അക്ഷരങ്ങളുടെ കോഡ് പോയിന്റ് ക്രമം ആയിരിക്കും.
ശ്രീകണ്ഠേശ്വരത്തിന്റെ ശബ്ദതാരാവലിയുടെ ആദ്യപതിപ്പുകൾ പക്ഷേ ര, ർ, ൎ എന്ന ക്രമവും, ല, വ, ശ, ഷ, സ, ഹ, ള, ഴ എന്നിവയ്ക്ക് ശേഷം ഏറ്റവും അവസാനം റ-യും കൊടുക്കുന്നു. ശബ്ദതാരാവലിയുടെ രണ്ടാംപതിപ്പാണ് ഞാൻ പരിശോധിച്ചത്. ശബ്ദതാരാവലിയുടെ പരിഷ്കരിച്ച പുതിയ പതിപ്പ് – പതിപ്പ് 39 – ഇതേ ക്രമം തന്നെയാണെങ്കിലും ബിന്ദുരേഫം- ൎ എടുത്തുകളഞ്ഞിരിക്കുന്നു.

സോഫ്റ്റ്വെയറുകളുടെ കാര്യം വരുമ്പോൾ നേരത്തെപ്പറഞ്ഞ എല്ലാ സിസ്റ്റങ്ങളും ഒരേ ക്രമം പിന്തുടരുന്നു.
ചന്ദ്രക്കല, ചില്ലക്ഷരങ്ങൾ, സംവൃതോകാരം
ചന്ദ്രക്കലയെ അകാരാദി ക്രമത്തിൽ എങ്ങനെ പരിഗണിക്കുന്നു എന്നതനുസരിച്ചു് അകാരാദിക്രമത്തിൽ വിവിധങ്ങളായ സമ്പ്രദായങ്ങൾ ഉണ്ടു്.
അകാരാദിക്രമത്തെ ലിപിസ്വരൂപത്തിന്റെ അടിസ്ഥാനത്തിൽ നിർവചിക്കുന്ന സമ്പ്രദായങ്ങളും, വർണ്ണവ്യവസ്ഥയുടെ(Phonetic nature) അടിസ്ഥാനത്തിൽ നിർവചിക്കുന്ന സമ്പ്രദായങ്ങളും ഉണ്ടു്. ലിപിസ്വരൂപത്തിൽ നിർവചിക്കുമ്പോൾ അക്ഷരമാലയിലെ സ്വരങ്ങളും, ക, ച, ട, ത, പ തുടങ്ങിയ വ്യഞ്ജനങ്ങളും ആണ് പ്രാഥമിക കണികകൾ. അതേ സമയം വർണ്ണവ്യവസ്ഥയിൽ വർണങ്ങളാണ് അടിസ്ഥാന കണികകൾ.
വർണം എന്നതുകൊണ്ട് ഉദ്ദേശിക്കുന്നതു് ഒരുദാഹരണം കൊണ്ടു് വ്യക്തമാക്കാൻ ക എന്ന അക്ഷരം എടുക്കുക. ഇതിലെ അടിസ്ഥാന ഉച്ചാരണ ഘടകം ക് എന്ന ശുദ്ധവ്യഞ്ജനം അഥവാ സ്വരം ചേരാത്ത വ്യഞ്ജനം ആണ്. ക എന്നതു് ക് + അ എന്നീ രണ്ട് വർണ്ണങ്ങൾ കൂടിച്ചേന്നതാണെന്നു വരുന്നു.
അതേ സമയം ക എന്നതു് പിരിക്കാനാകാത്ത ഒരു അക്ഷരമാണെന്ന അടിസ്ഥാനത്തിലാണ് പരിഗണിക്കുന്നതെങ്കിലോ? ക് എന്നത് ക യുടെ കൂടെ ചന്ദ്രക്കല ചേർന്ന രൂപമാണെന്നും വരുന്നു.
വർണം, അക്ഷരം, ലിപി എന്നിവ മാറിപ്പോകാതെ മനസ്സിലാക്കാൻ അവയെന്തെന്നു താഴെ വ്യക്തമാക്കുന്നു.
- വർണം – സ്വരം ചേരാത്ത ഉച്ചാരണയോഗ്യമല്ലാത്ത ശബ്ദഘടകം. ഉദാഹരണം ക്, ച്, ട്, ത്, പ്. സ്വനിമം (phoneme) എന്നും അറിയപ്പെടുന്നു.
- അക്ഷരം – വർണത്തിൽ സ്വരം ചേർത്ത ഉച്ചാരണയോഗ്യമായത്. ഇതിനായി വ്യഞ്ജനങ്ങളുടെ കൂടെ സ്വരങ്ങൾ ചേർക്കുന്ന. പൊതുസ്വരമായ അ ചേർത്തു് സ്വരചിഹ്നമില്ലാതെ ക എന്നെഴുതി ക് എന്ന വർണത്തെ ഉച്ചാരണസൌകര്യാർത്ഥം എഴുതുന്നു. ഒന്നിലധികം വ്യഞ്ജനങ്ങളും അക്ഷരം ആണ്. സ്വാതന്ത്ര്യം എന്ന വാക്കിൽ മൂന്ന് അക്ഷരങ്ങളുണ്ടെന്നാണ് നമ്മൾ പറയാറെന്നോർക്കുക. Syllable എന്നു ഇംഗ്ലീഷിൽ പറയാം.
- ലിപി – അക്ഷരങ്ങളെ എഴുതാൻ ഉപയോഗിക്കുന്ന ചിഹ്നങ്ങളുടെ വ്യവസ്ഥ
അകാരാദി എന്നും അക്ഷരമാലാക്രമം എന്നും പറയുമ്പോൾ വർണങ്ങൾ (phonemes) ആയി പിരിച്ച് അവയുടെ ക്രമമാണ് നോക്കേണ്ടത് എന്ന പ്രമാണമനുസരിക്കുന്ന സമ്പ്രദായം മിക്ക നിഘണ്ടുക്കളും പിന്തുടരാൻ ശ്രമിച്ചിട്ടുണ്ടു്.
ഉദാഹരണത്തിന് കടല്(ൽ), കടല എന്ന 2 വാക്കുകൾ, ശബ്ദതാരാവലി, പച്ചമലയാളം നിഘണ്ടു, സർവവിജ്ഞാനകോശം എന്നിവയെല്ലാം കടല്(ൽ), കടല എന്ന ക്രമത്തിൽ തന്നെ കൊടുക്കുന്നു.
പക്ഷേ ഗ്നു സി ലൈബ്രറിയൊഴികെയുള്ള സംവിധാനങ്ങൾ വർണങ്ങളെ അടിസ്ഥാനമാക്കിയല്ല ക്രമീകരിക്കുന്നതു്. ചന്ദ്രക്കലയും ചില്ലും എല്ലാ സ്വരചിഹ്നങ്ങളും കഴിഞ്ഞാണു് അവയിൽ വരുന്നതു്.

ചന്ദ്രക്കലയുടെ അതേ സ്വഭാവമല്ലേ ചില്ലിനും – സ്വരം ചേരാത്ത ശുദ്ധവ്യഞ്ജനം? ആ യുക്തി അനുസരിച്ച് ല്(ൽ) , ല എന്ന ക്രമം വരും. മുകളിൽ glibc സിസ്റ്റം ഈ രിതി പിന്തുടരുന്നതായി കാണാം.
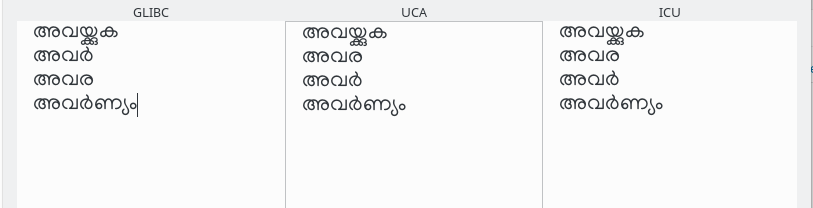
നിഘണ്ടുക്കളും അങ്ങനെത്തന്നെ.

ചന്ദ്രക്കലയുടെ ഉപയോഗം ചില്ലിനു സമാനമായ സ്വരമില്ലാത്ത വ്യഞ്ജനം ഉണ്ടാക്കലാണെന്നു പറഞ്ഞാൽ അതു് പൂർണ്ണമായും ശരിയാവില്ല. “അത്”, “കാല്”, “ചോറ്” എന്നീ വാക്കുകളൊക്കെ ഉച്ചരിച്ചുനോക്കൂ. കാല് എന്നതിലെ ല് ന്റെ ഉച്ചാരണമാണോ കാൽ എന്നതിലെ ൽ ന്റെ ഉച്ചാരണം? അല്ലല്ലോ? ഈ വ്യത്യാസത്തിന്റെ കാരണം മനസ്സിലാക്കാൻ സംവൃതോകാരം എന്താണെന്നറിയണം.
കാല് എന്നു പറയുമ്പോൾ ല് എന്നതിന്റെ ഉച്ചാരണത്തിൽ ല + ഉ + ് എന്നീ വർണങ്ങൾ അടങ്ങിയിട്ടുണ്ടു്. പക്ഷേ അതു് അതേപോലെ എഴുതുമ്പോൾ ലു് എന്നാണെഴുതേണ്ടതു്. കാലു് എന്ന്. ഈ ലേഖനത്തിൽ ഞാൻ ഈ ഉകാരവും ചന്ദ്രക്കലയും ഇട്ടെഴുതുന്ന ശൈലി വ്യാപകമായി ഉപയോഗിച്ചിരിക്കുന്നതു് ശ്രദ്ധിച്ചിരിക്കുമല്ലോ. ചുരുക്കത്തിൽ ഉ+് എന്നതിനെ സംവൃതോകാരം എന്നു വിളിക്കാം. കാലു് എന്നു് ഇന്നധികമാരും എഴുതാറില്ല. കാല് എന്ന് ലളിതമായെഴുതി ഉ കാരം കൂടി ഉച്ചരിക്കാറാണു പതിവ്. സംവൃതോകാരം കാണിക്കാൻ ഉ കാരം പ്രത്യേകം എഴുതേണ്ടതുണ്ടോ ഇല്ലയോ എന്ന കാര്യങ്ങളും സംവൃതോകാരത്തിന്റെ സ്വഭാവവും മലയാളവ്യാകരണവിദഗ്ദ്ധൻമാർക്കിടയിൽ വ്യാപകമായ ചർച്ച ചെയ്യപ്പെട്ട വിഷയമാണു്.
എന്തായാലും കാലു് എന്നു ഞാൻ എഴുതിയെന്നിരിക്കട്ടെ, അതിൽ ഉ ചിഹ്നമുണ്ടുതാനും. കാൽ, കാല്, കാല്, കാലു്, കാല എന്നീ വാക്കുകൾ ഏത് ക്രമത്തിൽ വരും?
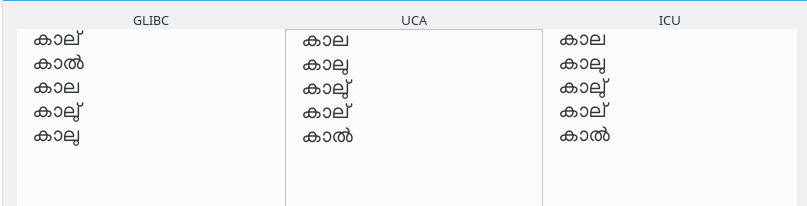
കാൽ, കാല് എന്നിവ കാല എന്നതിനു മുമേ വരുമെന്നു നമ്മൾ നേരത്തേ കണ്ടു. UCA, ICU(CLDR) എന്നിവ ആ ക്രമം പിന്തുടരുന്നില്ലെന്നും. കാലു്, കാലു എന്നിവയോ? അവയിലെ വർണങ്ങൾ പിരിച്ചെഴുതിനോക്കാം:
കാലു് = ക് + ആ + ല് + ഉ + ്
കാലു = ക് + ആ + ല് + ഉ
അതുപ്രകാരം ലു എന്നതിന്റെ പൂർണ്ണ ഉച്ചാരണത്തിലേക്കെത്താത്ത പാതിവഴിയാണ് കാലു്. അതുകൊണ്ട് കാലു്, കാല് എന്ന ക്രമം വരണം. ഈ ക്രമം glibc അനുസരിച്ചിരിക്കുന്നതു് താഴെക്കൊടുത്തിരിക്കുന്ന ചിത്രത്തിൽ ശ്രദ്ധിക്കുക.
നിഘണ്ടുകളിൽ അങ്ങനെ ഉകാരചിഹ്നമിട്ട് സംവൃതോകാമെഴുതുന്നതു് ഇക്കാലത്തെ നിഘണ്ടുക്കളിൽ ഇല്ലേയില്ല. ഗുണ്ടർട്ടിന്റെ നിഘണ്ടുവിൽ ചോറു, കാലു, കോഴിക്കോടു, വേണാടു. തുടങ്ങി പൂർണ്ണ ഉകാരമുമ്പയോഗിച്ചെഴുതുന്ന ശൈലിയാണുള്ളതു്. ശബ്ദതാരാവലിയുടെ ആദ്യകാല പതിപ്പിൽ സംവൃതോകാരം ഉകാരവും ചന്ദ്രക്കലയും ചേർത്തെഴുതുന്നുണ്ടു്. അതിൽ കാട, കാടി, കാടു്, കാടു എന്ന ക്രമം പിന്തുടരുന്നു. അതു് മേൽപ്പറഞ്ഞ വർണങ്ങളെ അടിസ്ഥാനമാക്കിയുള്ള യുക്തിയനുസരിച്ചുള്ളതാണു്.

സർവവിജ്ഞാനകോശത്തിൽ സംവൃതോകാരം ഉകാരലിപി ഉപയോഗിച്ച് എഴുതുന്നില്ലെങ്കിലും ഉകാര ചിഹ്നങ്ങളുടെ തൊട്ടുമുമ്പ് ക്രമീകരിച്ചിരിക്കുന്നു. “മലയാളത്തിൽ സംവൃതോകാരത്തിന് വ്യാകരണമൂല്യം പ്രകടമാകയാൽ അതിന് അകാരാദിയിൽ അംഗീകാരം നൽകിയിരിക്കുന്നു. പട്ട, പട്ട്, പട്ടു. വന്ന, വന്ന്, വന്നു. ചാർ – ചാറ -ചാറി -ചാറ്-ചാറുക ഈ ക്രമത്തിലാണ് അകാരാദി കണക്കാക്കേണ്ടത്.” എന്നു് കൊടുത്തിരിക്കുന്നു.
ഗുണ്ടർട്ടിന്റെ നിഘണ്ടുവിൽ ചില്ലക്ഷരങ്ങൾ എല്ലാം എല്ലാ സ്വരചിഹ്നങ്ങളും കഴിഞ്ഞ് അവസാനമാണ് വരുന്നതു്. എളുപ്പം, എൾ എന്ന ക്രമം വരുന്നുണ്ടു്. പക്ഷേ നേരെതിരിച്ച് കടൽ, കടല എന്ന ക്രമവും കാണുന്നതുകൊണ്ടു് ഇക്കാര്യത്തിൽ വ്യക്തത പോര.
മലയാള ചില്ലക്ഷരങ്ങളുടെ എൻകോഡിങ്ങിനെക്കുറിച്ചുള്ള നീണ്ട ചർച്ചകളിൽ ചന്ദ്രക്കല, സംവൃതോകാരം എന്നിവയുടെ നിർവചനങ്ങളും സ്വഭാവവും വലിയ ചർച്ചയായിരുന്നു. അകാരാദിക്രമത്തെ മുൻനിർത്തി ഇവയുടെ സ്വഭാവം വിശകലനം ചെയ്യുന്ന Chandrakkala, Samvruthokaram, Chillaksharam – from the perspective of Malayalam Collation എന്ന ഒരു പ്രബന്ധം ആർ. ചിത്രജകുമാർ, എൻ. ഗംഗാധരൻ എന്നിവർ ചേർന്നു് രചിച്ചിട്ടൂണ്ടു്. ഈ പ്രബന്ധത്തിൽ ഉകാരചിഹ്നമില്ലാതെ എഴുതുകയും സംവൃതമായി ഉച്ചരിക്കുകയും ചെയ്യുന്ന കാല്, അത് തുടങ്ങിയ ശൈലി PseudoSamvruthokaram എന്ന പേരിട്ട് റെഫർ ചെയ്യുന്നുണ്ടു്. സംവൃതമായി ഉച്ചരിക്കുന്നവ ഉകാരചിഹ്നത്തോടെ തന്നെ എഴുതുക വഴി ചില്ലക്ഷരത്തിന്റെ അറ്റോമിക് എൻകോഡിങ്ങ് അനാവശ്യമാകും എന്ന വാദം മുന്നോട്ടു വെയ്ക്കുന്നുണ്ടു്. സ്വനിമം/വർണങ്ങളായി അക്ഷരങ്ങളെ വേർപെടുത്തിയെഴുതി കൊളേഷൻ നിർണയിക്കുന്ന ആശയം GNU C Library യിൽ എഴുതാൻ എന്നെ ഈ പ്രബന്ധം വളരെ സഹായിച്ചിട്ടുണ്ടു്. അതു് വായിക്കണമെന്നഭ്യർത്ഥിക്കുന്നു.
ചില്ലക്ഷരങ്ങളുടെ എൻകോഡിങ്ങിനെപ്പറ്റി സൂചിപ്പിച്ചുവല്ലോ. ZWJ ഉപയോഗിച്ചെഴുതുന്ന ചില്ലുകളും (ന് = ന്+ZWJ) ഉം അറ്റോമിക് ആയി എൻകോഡ് ചെയ്ത ചില്ലുകളും ഉപയോഗത്തിലുണ്ടു്. ഈ രണ്ടു ചില്ലുകളെയും ഒരേ പോലെയാണ് glibc, icu, uca എന്നീ സോഫ്റ്റ്വെയർ സംവിധാനങ്ങളും ഇപ്പോൾ സോർട്ട് ചെയ്യുന്നതു്.
അനുസ്വാരം
അനുസ്വാരം – ം , മയുടെ ചില്ലായിട്ടാണ് അകാരാദിക്രമത്തിൽ പരിഗണിക്കുന്നതു്. ം == മ് അതിനാൽ ‘കനകം’ കഴിഞ്ഞേ ‘കനം’ വരൂ. ശബ്ദതാരാവലിയിൽ അങ്ങനെയാണ്. ഗുണ്ടർട്ടിൽ നേരെ മറിച്ചാണ് കാണുന്നത്. Glibc, ICU എന്നിവയും കനകം, കനം എന്നു ക്രമീകരിക്കുന്നു.

കൂട്ടക്ഷരങ്ങൾ
കൂട്ടക്ഷരങ്ങളുടെ ക്രമം അതിനെ വർണങ്ങളാക്കി പിരിച്ചു് ഇടത്തുനിന്നു വലത്തോട്ട് ഒരേസ്ഥാനത്തുള്ളവയുടെ ക്രമം കണക്കാക്കിയാണ്.
താഴെക്കൊടുത്തിരിക്കുന്ന ചിത്രത്തിൽ നിന്നും ഇക്കാര്യം മനസ്സിലാക്കാമെന്നു കരുതുന്നു.
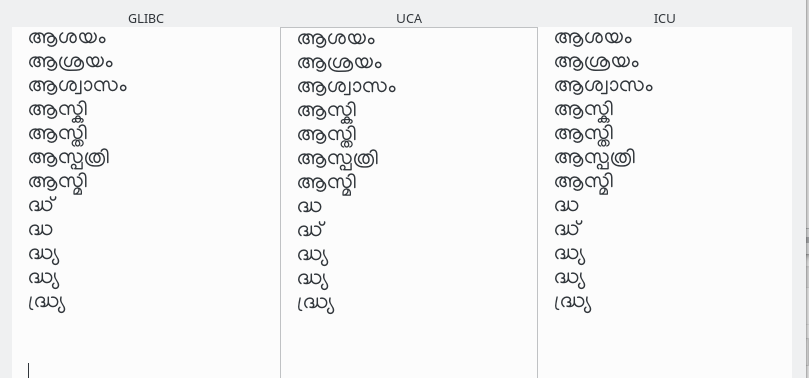
സമാന സ്വരചിഹ്നങ്ങൾ
മലയാളത്തിലെ ഔ ചിഹ്നത്തിനു് ൌ എന്നും ൗ എന്നും ചിഹ്നങ്ങൾ ഉണ്ടു്. പൌർണ്ണമി, പൗർണ്ണമി എന്നിവ ഉദാഹരണങ്ങൾ. ഈ രണ്ടു ചിഹ്നങ്ങളും ഒരേ സ്വനിമത്തെത്തന്നെ സൂചിപ്പിക്കുന്നതിനാൽ അടുത്തടുത്തുവരണം. നിഘണ്ടുക്കൾ ഇതിലേതെങ്കിലും ഒന്നേ ഉപയോഗിക്കാറുള്ളൂവെന്നതിനാൽ ഈ പ്രശ്നം ഉദിക്കുന്നില്ല. സോഫ്റ്റ്വെയർ ലൈബ്രറികളിൽ glibc, ICU എന്നിവ ഈ ബന്ധം തിരിച്ചറിയുന്നുണ്ട്.
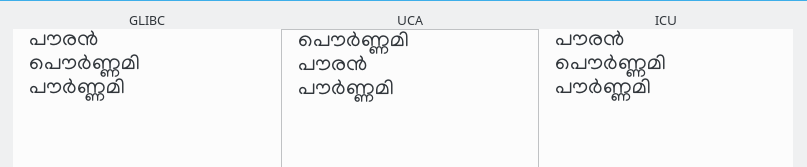
ഒ, ഓ, ഔ എന്നിവയുടെ സ്വരചിഹനങ്ങള് യഥാക്രമം ൊ , ോ , ൌ എന്നോ െ+ ാ , േ+ ാ , െ+ ൗ എന്നോ വേർപെടുത്തി എഴുതിയാലും തുല്യമായി കണക്കാക്കും(Canonical Equivalence.)
വിസർഗം, ഹ
ഹ, വിസർഗം എന്നിവയ്ക്ക് സമാന ഉച്ചാരണമായതിനാൽ അവ അടുത്തടുത്തുവരണമെന്നൊരു പ്രമാണം കേട്ടിട്ടുണ്ടെങ്കിലും നല്ലൊരു ഉദാഹരണം അറിയില്ല. ഏതെങ്കിലും നിഘണ്ടുവിലോ സോഫ്റ്റ്വെയർ ലൈബ്രറികളിലോ ഇങ്ങനെ ക്രമീകരിച്ചതായി അറിയില്ല.
റ്റ
ഗുണ്ടർട്ടിന്റെ നിഘണ്ടുവിലെപ്പോലെത്തന്നെ റയ്ക്ക് ശേഷം റ്റ ശബ്ദതാരാവലി രണ്ടാം പതിപ്പും പിന്തുടരുന്നു. മാത്രമല്ല, ശബ്ദതാരാവലിയുടെ ഇന്നത്തെ മുപ്പത്തൊമ്പതാം പതിപ്പും, സുമംഗലയുടെ പച്ചമലയാളം നിഘണ്ടുവും ഇതേ ക്രമം പിന്തുടരുന്നു.

റ്റ = റ + ് + റ എന്ന യുണിക്കോഡ് രീതിവെച്ച്, റയുടെ തൊട്ടുശേഷം തന്നെ റ്റ വരും. ഇത് എല്ലാ ലൈബ്രറികളും ഒരു പോലെ പിന്തുടരുന്നു. എങ്കിലും നേരത്തെപ്പറഞ്ഞ ചന്ദ്രക്കലയുടെ വ്യത്യാസമുണ്ടെന്നു ഓർക്കണം.

റ്റ യഥാർത്ഥത്തിൽ ഺ ഖരമായും ഩ അനുനാസികമായും വരുന്ന ഒരു വ്യഞ്ജനവർഗത്തിലെ ഺ യുടെ ഇരട്ടിപ്പാണെന്നു കേരളപാണിനീയം പറയുന്നുണ്ടെങ്കിലും ഺ യും റ്റ യും തമ്മിൽ ഒരു ബന്ധവും ഒരു കൊളേഷൻ സിസ്റ്റവും കൊടുക്കുന്നില്ല.
മലയാള അക്കങ്ങൾ
മലയാളം അക്കങ്ങള് അവയുടെ അറബി ലിപികളുടെ കൂടെ തന്നെ വരും. മറ്റുഭാഷകളിലെ അക്കങ്ങൾ ഉണ്ടെങ്കിലും അടുത്തടുത്തുവരും.
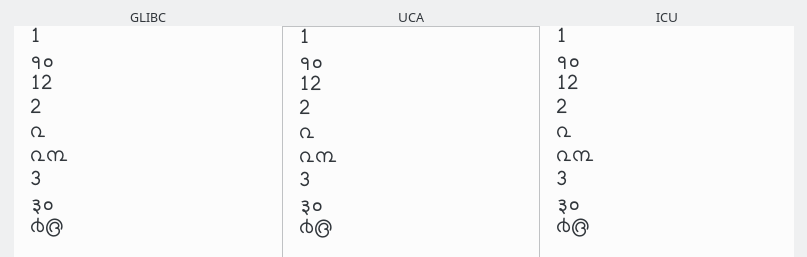
പ്രാധാന്യം
ഒരു നീണ്ട പട്ടികയിൽ നിന്നും പെട്ടെന്നൊരു പേരോ മറ്റോ കണ്ടുപിടിക്കുന്നതിനു അകാരാദിക്രമം സഹായിക്കും. അതുപക്ഷേ ഇന്നത്തെ കാലത്തെ സോഫ്റ്റ്വെയറുകൾ സെർച്ച് ഫീച്ചർ തരുമെങ്കിലും. തെരഞ്ഞുകണ്ടുപിടിക്കലിലൊതുങ്ങുന്നില്ല, ഒരു പട്ടികയലെ സ്ഥാനവും അകാരാദിക്രമമാണ് തീരുമാനിക്കുന്നതു്. ഉദാഹരണത്തിനു് ഒരു ക്ലാസിലെ ഒരു കുട്ടിയുടെ റോൾ നമ്പർ ക്ലാസിലെ കുട്ടികളുടെ പേരുകൾ സോർട്ട് ചെയ്ത ക്രമമായിരിക്കും തീരുമാനിക്കുന്നതു്.
നിഘണ്ടുക്കളിലും സോഫ്റ്റ്വെയർ സിസ്റ്റങ്ങളിലും അകാരാദിക്രമത്തിന്റെ കാര്യത്തിൽ ഏകീകൃതസ്വഭാവം ഇല്ല എന്നു മനസ്സിലായല്ലോ. ഏകീകൃതമായ ഒരു ക്രമം ഇല്ലാത്തതിന്റെ കാരണം സാങ്കേതികമല്ല. അങ്ങനെ ഒരു ക്രമത്തിന്റെ നിർവചനം ലഭ്യമല്ല എന്നതുകൊണ്ടാണ്. ആരായിരിക്കും അങ്ങനെ ഔദ്യോഗികമായി ഒരു ക്രമം നിർവചിക്കേണ്ടതു്? യഥാർത്ഥത്തിൽ അകാരാദിക്രമത്തിന്റെ മാനകീകരണത്തെപ്പറ്റി മലയാളം ഉപയോക്താക്കൾ ബോധമുള്ളവരാണോ? എന്തെങ്കിലും പ്രശ്നം അതുണ്ടാക്കുന്നുണ്ടോ? ഇല്ലെങ്കിൽ ഇതു് വെറുമൊരു “പെർഫക്ഷൻ” ഇഷ്യൂ ആണോ?
സാങ്കേതികക്കുറിപ്പുകൾ
- glibc collation: ഇതിന്റെ ആദ്യപതിപ്പ് 2009ൽ ആണെഴുതുന്നതു്. പക്ഷേ പിന്നീട് ശ, ഷ, സ എന്നിവയുടെ ക്രമത്തിൽ ഒരു പിശക് ശ്രദ്ധയിൽ പെടുകയും തിരുത്തുകയും ചെയ്തിട്ടുണ്ടു്. അറ്റോമിക് ചില്ലുകൾ ചേർത്തിട്ടില്ലായിരുന്നതിനാൽ അതും ഇപ്പോൾ ചേർത്തിട്ടുണ്ട്. ഈ മാറ്റങ്ങളെല്ലാം ചേർന്ന glibc യുടെ പതിപ്പ് 2.26 ൽ ആണ് വരുന്നതു്. അതു് ഉബുണ്ടുവിന്റെ അടുത്ത മാസം വരുന്ന പതിപ്പിൽ വരും. ഈ ലേഖനത്തിലെ അകാരാദിക്രമം glibc യുടെ ഈ മാറ്റങ്ങളെല്ലാം ഉള്ള പതിപ്പിലാണ് ടെസ്റ്റ് ചെയ്തിരിക്കുന്നതു്.
- CLDR അടിസ്ഥാനമാക്കിയുള്ള ICU കൊളേഷൻ സംവിധാനം ബ്രൌസറുകളിലൊക്കെ ജാവാസ്ക്രിപ്റ്റിൽ നിലവിലുണ്ടു്. അതെങ്ങനെ ഉപയോഗിക്കാമെന്നതിന്റെ ചെറിയൊരു ഡെമോ: https://codepen.io/santhoshtr/pen/NjMXjE
- ഈ ലേഖനത്തിൽ മൂന്നു വ്യത്യസ്ത സോഫ്റ്റ്വെയർ സംവിധാനങ്ങളിലെ അകാരാദിക്രമം കാണിക്കാൻ വേണ്ടി ചെറിയൊരു അപ്ലിക്കേഷൻ പൈത്തൺ ഉപയോഗിച്ചെഴുതിയിട്ടുണ്ട്. അതിന്റെ സോഴ്സ് കോഡ്: https://gist.github.com/santhoshtr/681e8bb72c63cb74d67d123f4fb7e7be
- ചിലയിടത്തു് രണ്ടക്ഷരങ്ങളും തുല്യമായി പരിഗണിക്കും എന്ന് ലേഖനത്തിൽ പറയുമ്പോൾ, അകാരാദിക്രമത്തിൽ അതിനെ മനസ്സിലാക്കേണ്ടത് ഇങ്ങനെയാണ്: അക്ഷരങ്ങൾക്കെല്ലാം ഒരു കൊളേഷൻ വെയിറ്റ് ഉണ്ടു്. അത് ഒരു സംഖ്യ ആണെന്നു കരുതുക. ഇത് തന്നെ പ്രൈമറി കൊളേഷൻ വെയിറ്റ്, സെക്കന്ററി കൊളേഷൻ വെയിറ്റ് എന്നിങ്ങനെ കൂടുതൽ ലെവലുകളാക്കി തിരിച്ചിരിക്കുന്നു. രണ്ട് അക്ഷരങ്ങൾ തുല്യമെന്നൊക്കെ പറയുമ്പോൾ പ്രൈമറി കൊളേഷൻ വെയിറ്റ് തുല്യമാണെന്നും സെക്കന്ററി കൊളേഷൻ വെയിറ്റ് വ്യത്യാസപ്പെട്ടു്, അക്ഷരങ്ങളിലേതു് ആദ്യം വരണമെന്നും തീരുമാനിക്കുന്നു. പ്രൈമറി കൊളേഷൻ വെയിറ്റ് തുല്യമായ അക്ഷരങ്ങളെ string comparison, string search എന്നിവയിലൊക്കെ തുല്യമായി പരിഗണിക്കണം.
- glibc പുതിയ യൂണിക്കോഡ് കോഡ്പോയിന്റുകൾ പരിഗണിക്കുന്നില്ല.
പരിശോധിച്ച നിഘണ്ടുക്കൾ
- A Malayalam And English Dictionary – H Gundert, 1871
- ശബ്ദതാരാവലി – രണ്ടാം പതിപ്പ്. ശ്രീകണ്ഠേശ്വരം ജി പത്മനാഭപിള്ള, 1931
- ശബ്ദതാരാവലി പരിഷ്കരിച്ച പുതിയ പതിപ്പ്: മുപ്പത്തൊമ്പതാം പതിപ്പ് – സാഹിത്യ പ്രവർത്തക സഹകരണ സംഘം. 2013
- പച്ചമലയാളം നിഘണ്ടു – സുമംഗല – ഗ്രീൻബുക്സ്, 2016
നിഘണ്ടുക്കളിൽ ആദ്യാവസാനം ഏകദേശം ഒരേ ക്രമം പിന്തുടരുന്നെങ്കിലും മനുഷ്യപ്രയത്നഫലമായതിനാൽ ചില നോട്ടപ്പിശകുകൾ ഒക്കെ ഉണ്ട്. ഉദാഹരണത്തിനു് ശബ്ദതാരാവലി രണ്ടാം പതിപ്പിൽ {ചക്കു്, ചക്ക}, {ചങ്കിടി, ചക്കു്} തുടങ്ങിയ ക്രമങ്ങളിൽ സംവൃതോകാരം പലയിടത്തായി വന്നിരിക്കുന്നു.